







Data Warehousing Explained: Transform your raw data into actionable insights with strategic storage, enhancing decision-making and business intelligence capabilities.
For businesses to thrive in today’s dynamic and data-driven world, they need to have efficient and organized data management systems. Although traditional databases serve the purpose of storing data, they are often not enough to handle large volumes of data and complex data analysis requirements.
This is where data warehousing comes in – a powerful tool for businesses to manage and analyze their data to gain valuable insights.
Understanding Data Warehousing
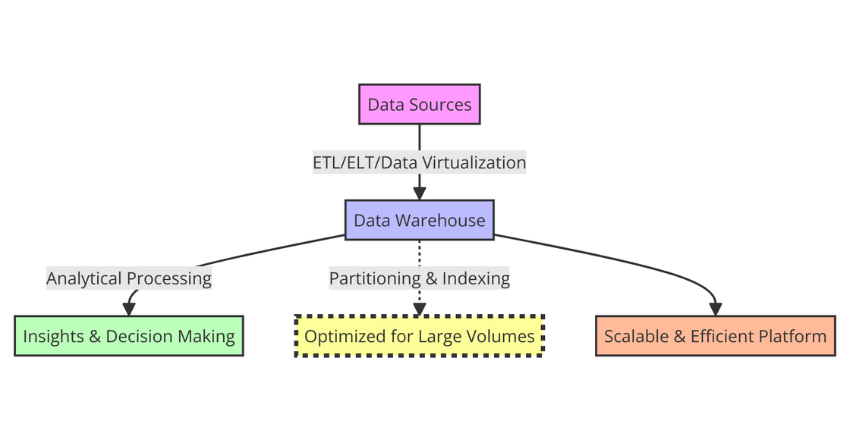
Data warehousing is a powerful tool used to manage and analyze large volumes of data. Unlike traditional databases, data warehousing offers a centralized and comprehensive solution for organizing and accessing data. By consolidating data from various sources into a single repository, data warehousing provides a holistic view of an organization’s data, enabling better decision-making and improved business outcomes.
Data warehousing is designed for analytical processing, allowing users to query and analyze data at various levels of granularity. This means that instead of just retrieving individual data points, users can retrieve and analyze entire data sets, gaining insights into trends, patterns, and relationships within their data.
One of the key features of data warehousing is its ability to handle large volumes of data. Data warehousing is optimized for read-heavy workloads, making it ideal for organizations that need to process and analyze vast amounts of data quickly and efficiently. By using techniques such as partitioning and indexing, data warehousing can provide fast query performance even on large datasets.
Another advantage of data warehousing is its ability to integrate disparate data sources. Data warehousing supports a range of data integration methods, including ETL (extract, transform, load), ELT (extract, load, transform), and data virtualization. This means that data from various sources such as databases, spreadsheets, and cloud-based applications can be consolidated and analyzed together in a single data warehouse.
Overall, data warehousing is a powerful and comprehensive solution for managing and analyzing large volumes of data. Whether you’re a small business or a large enterprise, data warehousing can provide a scalable and efficient platform for storing and processing your data.

Key Components of a Data Warehouse
At the heart of any data warehousing solution is a data warehouse, a centralized repository that stores data from various sources in a structured format. To build a robust and scalable data warehouse, it is essential to understand the key components that make up this environment.
Data Sources
A data warehouse is only useful if it contains high-quality data. Data sources are the inputs that feed into the data warehouse. They can come from a variety of sources, such as transactional systems, legacy databases, or external data feeds. These data sources can be different in size, structure, and format, requiring different data integration methods to bring them into the data warehouse.
Data Integration
Data integration is the process of combining data from different sources into a single, unified view. There are several data integration methods used in data warehousing, including extract, transform, and load (ETL) processes, data replication, and virtualization. ETL processes are the most common method used to integrate data into a data warehouse.
Data Storage
The data storage layer is where the data is physically stored in a data warehouse. It is typically divided into two parts: the data storage area and the indexing area. The data storage area holds the raw data, while the indexing area contains metadata, which are used to index and manage the data.
In addition, data warehouses use a variety of storage techniques, such as partitioning, compression, and indexing, to optimize data retrieval and querying performance.
Benefits of Data Warehousing

Implementing a data warehousing solution offers numerous benefits to businesses, including:
- Improved data quality: Data warehousing allows for data to be cleaned, standardized, and enriched, resulting in more accurate and reliable information for decision-making.
- Faster query performance: By pre-aggregating and indexing data, data warehouses can execute complex queries more quickly than traditional databases.
- Enhanced decision-making capabilities: Data warehousing provides decision-makers with access to a single, comprehensive source of data that can be used to generate insights and inform strategic decisions.
- Ability to handle large volumes of data: Data warehousing is designed to handle and process large volumes of data from multiple structured and unstructured sources, providing businesses with the ability to work with petabytes of data.
By implementing a data warehousing solution, businesses can gain a competitive edge and make better-informed decisions based on accurate and timely data.
Data Warehousing Architecture
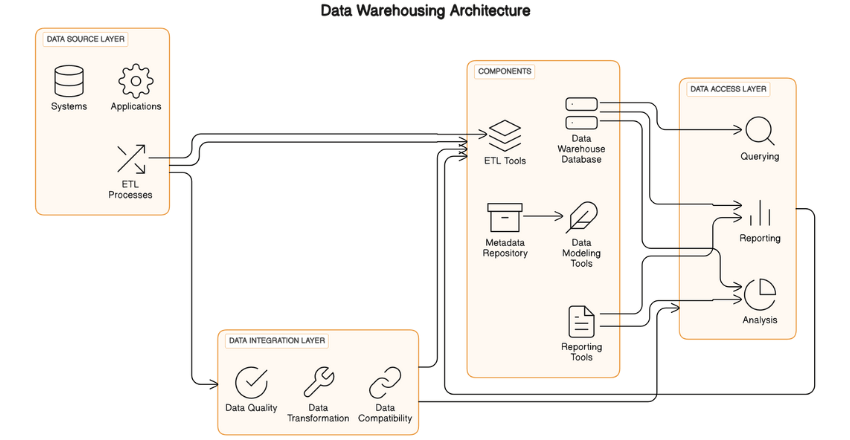
Data warehousing architecture is the design and structure of a data warehouse system that supports the storage, management, and analysis of large volumes of data. The architecture involves various layers of components that work together to provide a scalable and efficient solution for data warehousing operations.
Data Warehouse Layers
There are three primary layers in a data warehouse:
- The bottom layer is the data source layer, which consists of the systems and applications that generate data. This layer involves the extraction of data from various sources using ETL processes, as discussed in section 5.
- The middle layer is the data integration layer, which involves the transformation of data into a format that conforms to the data warehouse schema. This layer is responsible for ensuring data quality, consistency, and compatibility.
- The top layer is the data access layer, which provides end-users with access to the data warehouse for querying, reporting, and analysis.
Data Warehouse Components
There are several components involved in a data warehousing system:
| Component | Description |
|---|---|
| Data Warehouse Database | The database that stores the data warehouse schema and data. Typically optimized for query performance and scalability. |
| ETL Tools | Tools used for extracting, transforming, and loading data from various sources into the data warehouse. ETL processes are discussed in section 5. |
| Data Modeling Tools | Tools used for designing and managing the data warehouse schema, including data structures, relationships, and constraints. Data modeling is discussed in section 6. |
| Metadata Repository | A repository that stores information about the data warehouse schema, data sources, ETL processes, and data lineage. |
| Reporting Tools | Tools used for generating reports and visualizations based on the data stored in the data warehouse. |
Scalable Data Warehousing Architecture
A scalable data warehousing architecture is crucial for organizations dealing with large volumes of data. A well-designed architecture allows for the efficient storage and processing of data, while also providing fast and reliable access to end-users.
There are several best practices to follow when designing and implementing a scalable data warehousing architecture:
- Use a distributed architecture to distribute data and processing across multiple nodes.
- Choose a database management system optimized for query performance, scalability, and reliability.
- Implement data partitioning to distribute data across multiple physical storage devices.
- Use compression and indexing to optimize storage efficiency and query performance.
- Implement a data backup and recovery strategy to ensure data availability and reliability.
By following these best practices, organizations can achieve a scalable and efficient data warehousing architecture that supports their data management and analysis needs.
ETL Processes in Data Warehousing
Extract, Transform, and Load (ETL) processes are a critical component of data warehousing. ETL is the process of extracting data from multiple sources, transforming it into a format that can be loaded into a data warehouse, and then loading the data into the data warehouse.
The first step in the ETL process is to extract data from the source systems. This can be done using various methods such as bulk loading, change data capture, or real-time data replication. Once the data is extracted, it is transformed to match the schema of the target data warehouse.
This may include data cleansing, data manipulation, and data integration. Finally, the transformed data is loaded into the data warehouse for analysis and reporting purposes.
ETL processes can be complex and time-consuming, especially when dealing with large volumes of data. SQL code can be helpful in automating the ETL process and reducing the time and effort required.
For example, a SQL script can be used to extract data from multiple sources, perform data transformations, and load the transformed data into the data warehouse.
Efficient ETL processes are critical to the success of a data warehousing solution. They ensure that data is accurately and consistently loaded into the data warehouse, improving the accuracy and completeness of analytical reports and reducing the risk of data inconsistencies and errors.
Data Modeling in Data Warehousing
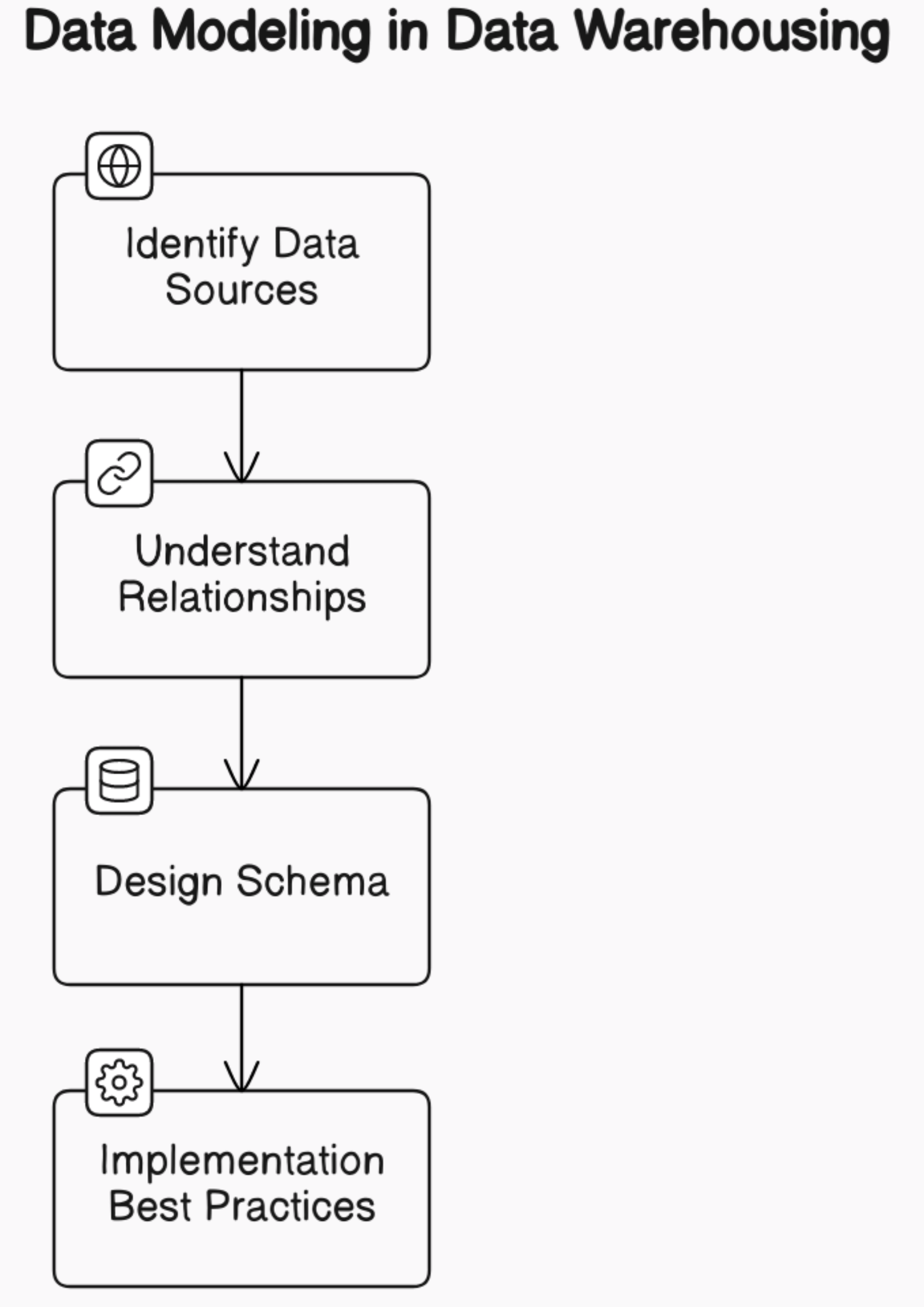
In data warehousing, data modeling is the process of creating a conceptual and logical representation of the data that will be stored in the data warehouse. It involves identifying the data sources, understanding the relationships between different data elements, and designing a schema that supports efficient querying and analysis. The primary goal of data modeling is to create a structure that is optimized for the specific needs of the organization.
Data modeling is a critical step in data warehousing because it defines the structure of the data that will be stored in the data warehouse. The data model determines the way that data is organized and stored in the warehouse, which has a direct impact on the performance of the system. A well-designed data model can make it easier to retrieve and analyze data, while a poorly designed model can lead to slow query times and inaccurate results.
There are several different data modeling techniques and methodologies that are commonly used in data warehousing. One approach is to use a star schema, which is a type of schema that organizes data into a central fact table surrounded by several dimension tables. Another approach is to use a snowflake schema, which is similar to the star schema, but with additional levels of normalization.
In addition to choosing the appropriate schema for the data warehouse, it is important to follow best practices when designing and implementing the model.
This includes standardizing naming conventions, defining data types and constraints, and documenting any assumptions or decisions that were made during the modeling process.
SQL code can be used to create and modify data models in a data warehousing environment. For example, a CREATE TABLE statement can be used to define the structure of a new table, while an ALTER TABLE statement can be used to modify an existing table.
SQL code can also be used to create indexes, constraints, and other elements of the data model.
Example
Given the importance of data modeling in data warehousing and the foundational role it plays in ensuring efficient querying and analysis, let’s explore an example using the star schema approach, which is one of the most commonly used schemas in data warehousing due to its simplicity and effectiveness in handling analytical queries.
Star Schema Example: Sales Data Warehouse
In this example, we’ll design a simple star schema for a sales data warehouse. The schema will include a central fact table that records sales transactions and several dimension tables that provide context about those transactions (e.g., product details, customer information, time of sale).
Fact Table: FactSales
This table stores transactional data, with each row representing a sale. It includes foreign keys to dimension tables.
CREATE TABLE FactSales (
SaleID INT PRIMARY KEY,
DateKey INT NOT NULL,
ProductKey INT NOT NULL,
CustomerKey INT NOT NULL,
SalesAmount DECIMAL(10, 2),
QuantitySold INT,
FOREIGN KEY (DateKey) REFERENCES DimDate(DateKey),
FOREIGN KEY (ProductKey) REFERENCES DimProduct(ProductKey),
FOREIGN KEY (CustomerKey) REFERENCES DimCustomer(CustomerKey)
);Dimension Table: DimProduct
Stores information about products. Each row represents a unique product.
CREATE TABLE DimProduct (
ProductKey INT PRIMARY KEY,
ProductName VARCHAR(255),
Category VARCHAR(50),
Price DECIMAL(10, 2)
);Dimension Table: DimCustomer
Contains details about customers. Each row represents a unique customer.
CREATE TABLE DimCustomer (
CustomerKey INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Email VARCHAR(100),
Region VARCHAR(50)
);Dimension Table: DimDate
Provides information about dates, facilitating time-based analysis.
CREATE TABLE DimDate (
DateKey INT PRIMARY KEY,
Date DATE,
Weekday VARCHAR(10),
Month VARCHAR(10),
Year INT,
Quarter INT
);Implementing the Model
- Standardizing Naming Conventions: Notice the consistent use of “Key” for primary and foreign keys, and the prefix “Dim” for dimension tables. This clarity and consistency are crucial in data modeling.
- Defining Data Types and Constraints: Each table definition includes data types that reflect the nature of the data (e.g.,
DECIMALfor financial amounts,INTfor keys) and constraints to ensure data integrity. - Documenting Assumptions: It’s essential to document any assumptions or decisions made during the modeling process. For example, documenting the choice of a star schema over a snowflake schema due to its simplicity and performance benefits for your specific analytical needs.
This example illustrates a foundational structure for a sales data warehouse using a star schema. The simplicity of the star schema allows for efficient data retrieval for analytical queries, making it a popular choice for many data warehousing projects.
Data Warehousing Vs. Traditional Databases
Data warehousing provides a powerful and organized data solution that traditional databases simply cannot match. While traditional databases are designed to handle day-to-day transactional data, data warehousing is specifically optimized for analytical processing and complex queries. Here are some key differences:
| Data Warehousing | Traditional Databases |
|---|---|
| Optimized for complex queries and analytical processing | Optimized for day-to-day transactional data |
| Supports multiple data sources and formats | Only supports a limited number of data sources and formats |
| Can handle large volumes of data | Not designed to handle large volumes of data |
| Stores historical data for trend analysis | Does not store historical data |
Data warehousing allows for data consolidation from multiple sources, which traditional databases cannot handle efficiently. The data modeling techniques used in data warehousing deliver a simpler data structure for quick and easy querying. Traditional databases may require complex joins, subqueries, or nested queries to extract relevant information, which can be time-consuming.
Data warehousing also offers superior query performance because it uses a specialized architecture optimized for reading data. Traditional databases are optimized for writing data, so their query performance may not meet the same standards. In addition, data warehousing supports sophisticated analytics including trend analysis and predictive modeling, which can deliver insights that a traditional database cannot provide.
Overall, data warehousing offers a more robust and comprehensive data solution than traditional databases, providing better data quality, faster query performance, and advanced analytics capabilities.
Best Practices in Data Warehousing

Data warehousing can be a complex process, and there are several best practices that organizations should follow to ensure a successful implementation. These practices cover data governance, performance optimization, security, and scalability to name a few.
Data Governance
Implementing a sound data governance strategy is crucial to ensure the success of a data warehousing solution. This strategy should include clear policies and procedures for data management, as well as guidelines for data access and usage. Additionally, regular audits should be conducted to help maintain data quality and integrity.
Performance Optimization
Performance optimization is another key area to focus on when implementing a data warehousing solution. This involves designing an efficient data model and developing effective indexing strategies to support fast querying and analysis. Additionally, appropriate hardware and software configurations should be selected to support the performance requirements of the solution.
Security
Securing a data warehousing solution is critical, as it contains sensitive and valuable data. Access controls, data encryption, and network security measures should be implemented to ensure the security and integrity of the data. Regular security audits and risk assessments should also be conducted to maintain a strong security posture.
Scalability
Finally, scalability is a crucial consideration when designing a data warehousing solution. The solution should be designed to handle large volumes of data effectively and efficiently, and it should be able to scale as data volumes increase over time. This can be achieved through the use of scalable hardware and software solutions and the implementation of effective data partitioning strategies.
By following these best practices, organizations can ensure the success of their data warehousing initiatives and unlock the full potential of their data.
Final Thoughts

Data warehousing is a powerful tool for managing and analyzing large volumes of data. By providing a centralized and organized data repository, it allows for faster query performance and more informed decision-making. Implementing a data warehousing solution can seem daunting, but it’s important to remember that it’s a long-term investment that will pay off in the end.
At HireSQL, we understand the importance of data warehousing and have a team of dedicated SQL developers who can help implement a solution tailored to your business needs. Our developers are fluent in English and based in South America, providing cost-effective solutions without sacrificing quality.
If you’re interested in learning more about data warehousing or need assistance with implementing a solution, contact us today. We’ll be happy to discuss your project and provide a free consultation.
External Resources
https://www.techtarget.com/searchdatamanagement/definition/data-governance
FAQ

FAQ 1: What is a Data Warehouse and why is it important for businesses?
Answer: A Data Warehouse is a centralized repository designed to store integrated data from multiple sources. It supports analytical reporting, structured and/or ad hoc queries, and decision making. Data Warehouses are crucial for businesses because they provide a coherent picture of the business at a point in time, enabling data-driven decisions.
Explanation: ETL processes are foundational to Data Warehousing. “Extract” involves gathering data from multiple sources, “Transform” refers to cleaning and organizing this data into a consistent format, and “Load” means inserting the data into the warehouse.
Tools like SQL Server Integration Services (SSIS) or Azure Data Factory can be used to automate these tasks.
FAQ 2: How do you ensure the quality of data in a Data Warehouse?
Answer: Ensuring data quality in a Data Warehouse involves several strategies, including data validation, cleansing, and deduplication. Implementing comprehensive ETL processes with validation checks is crucial for maintaining high-quality data.
Code Sample: Here’s a simple SQL example for data validation and cleansing, assuming we’re loading customer data into a Data Warehouse.
-- Example SQL for identifying duplicates
SELECT CustomerID, COUNT(*)
FROM Customers
GROUP BY CustomerID
HAVING COUNT(*) > 1;
-- Example SQL for removing duplicates (simple scenario)
WITH RankedCustomers AS (
SELECT *, ROW_NUMBER() OVER(PARTITION BY CustomerID ORDER BY UpdateDate DESC) AS Rank
FROM Customers
)
DELETE FROM RankedCustomers WHERE Rank > 1;Explanation: The first query identifies duplicate records for the same customer, which is a common data quality issue. The second query shows a method to remove duplicates by keeping only the most recently updated record for each customer. This is a simplification, and real-world scenarios often require more complex logic.
FAQ 3: What are the best practices for structuring a Data Warehouse?
Answer: Best practices for structuring a Data Warehouse include adopting a dimensional modeling approach, such as the star or snowflake schema, for organizing data into fact and dimension tables. This optimizes query performance and simplifies data analysis.
Code Sample: A basic example of creating tables in a star schema for a retail sales Data Warehouse:
-- Creating a Fact table
CREATE TABLE FactSales (
SaleID INT PRIMARY KEY,
ProductID INT,
DateID INT,
CustomerID INT,
QuantitySold INT,
TotalSaleAmount DECIMAL
);
-- Creating Dimension tables
CREATE TABLE DimProduct (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(255),
Category VARCHAR(255)
);
CREATE TABLE DimDate (
DateID INT PRIMARY KEY,
Date DATE,
WeekdayName VARCHAR(255),
MonthName VARCHAR(255),
Year INT
);
CREATE TABLE DimCustomer (
CustomerID INT PRIMARY KEY,
FirstName VARCHAR(255),
LastName VARCHAR(255),
Email VARCHAR(255)
);Explanation: In this example, FactSales is the fact table that stores transactional data like QuantitySold and TotalSaleAmount. DimProduct, DimDate, and DimCustomer are dimension tables that store attributes about products, dates, and customers, respectively.
This structure supports efficient querying and analysis, as it allows for easy joining of tables to analyze sales data across different dimensions.
