







Database clustering optimizes performance and scalability, distributing workloads across multiple nodes to handle growing data demands efficiently.
Modern database management systems require high availability and efficient data distribution to provide optimal performance. Database clustering is an essential technique used to achieve these goals.
What is Database Clustering?
Database clustering is a technique that involves combining multiple servers to act as a single logical system. This allows for efficient data distribution and high availability, ensuring that database services remain online in case of hardware failures or other disruptions.
Unlike traditional single-server databases, clustering enables organizations to scale their computing resources dynamically, meet growing business needs, and provide reliable services to end-users despite high traffic loads.
Clustered databases use specialized algorithms to distribute and replicate data across multiple nodes, providing redundancy and resiliency. This makes them ideal for organizations that require continuous access to large amounts of data. By using clustering, businesses can improve their overall performance and provide uninterrupted services to their customers.
Types of Database Clustering
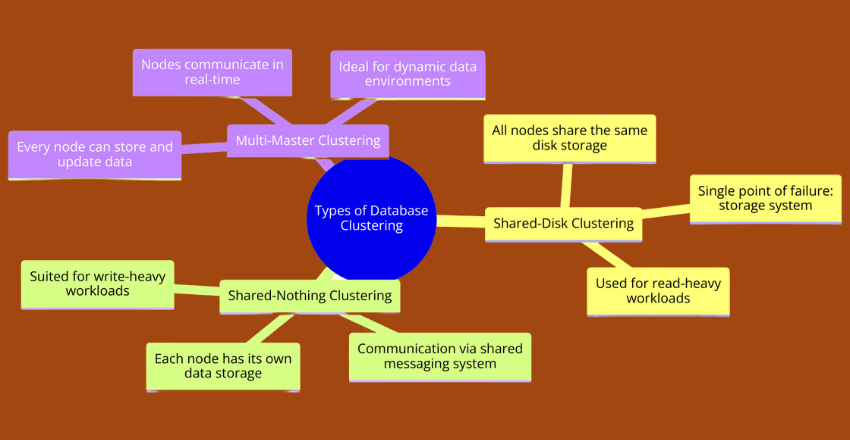
Database clustering is a key approach organizations implement for achieving high availability. Database clustering techniques typically fall into three categories: shared-disk clustering, shared-nothing clustering, and multi-master clustering.
Shared-Disk Clustering
In shared-disk clustering, all nodes in the cluster share access to the same disk storage. This allows for quick and easy access to data, but it can also create a single point of failure if the storage system were to fail. Shared-disk clustering is commonly used for read-heavy workloads such as reporting and analytics where high-performance access to data is critical.
Shared-Nothing Clustering
With shared-nothing clustering, each node in the cluster retains its own data storage, and communication is performed via a shared messaging system. This architecture effectively eliminates the single point of failure that comes with shared-disk clustering but may introduce problems with data consistency and synchronization. Shared-nothing clustering is best suited for write-heavy workloads such as transaction processing where data consistency is key.
Multi-Master Clustering
Multi-master clustering offers the best of both worlds: every node in the cluster can store and update data, and all nodes communicate with one another in real-time. Multi-master clustering is well-suited for highly dynamic data environments where data is frequently updated and accessed from multiple sources.
The choice of cluster type will depend on the organization’s specific needs and use cases. In most cases, a hybrid approach that combines shared-disk clustering and shared-nothing clustering will be most effective for achieving high availability and efficient data distribution.
Here’s an SQL example demonstrating the distinction between the different types of clustering:
SELECT * FROM employees WHERE salary > 50000;Shared-disk clustering provides the fastest response time for this query, as the data is accessed from a single source. Shared-nothing clustering, on the other hand, may require more time to complete this query as it may need to search through multiple nodes for the requested data. Multi-master clustering is ideally suited for distributing data across nodes and ensuring high availability, but it may introduce additional complexity that requires careful management and monitoring.

Setting up a Database Cluster
In order to set up a database cluster, there are a few important steps that need to be followed. Firstly, the cluster nodes need to be configured and connected. The nodes must be able to communicate with one another to share data effectively and this can be achieved through a shared network connection. Once the nodes are connected, the next step is to establish a communication channel between them. This usually involves opening specific ports and configuring firewall settings to allow traffic between nodes.
The next crucial step is to ensure that data is replicated across the cluster. This can be done through a process called data partitioning, where data is broken up into smaller pieces and distributed across the cluster. This ensures that no single node becomes a bottleneck for the cluster.
There are various tools and techniques available to help with setting up a database cluster, including open-source solutions like MySQL Cluster and commercial solutions like Oracle RAC. It’s important to choose the right tools for your specific use case, based on factors like your data management needs and budget considerations.
If you are a SQL developer tasked with setting up a database cluster, having a strong understanding of SQL and database clustering is crucial. Here’s an example of SQL code that can be used to set up a basic cluster:
CREATE DATABASE mydatabase;
CREATE TABLE mytable (id INT, name VARCHAR(50));
INSERT INTO mytable (id, name) VALUES (1, "John");
SELECT * FROM mytable;Overall, setting up a database cluster can be a complex process, but with the right tools and expertise, it can be done smoothly and efficiently, providing high availability and efficient data distribution for your organization.
Managing a Database Cluster
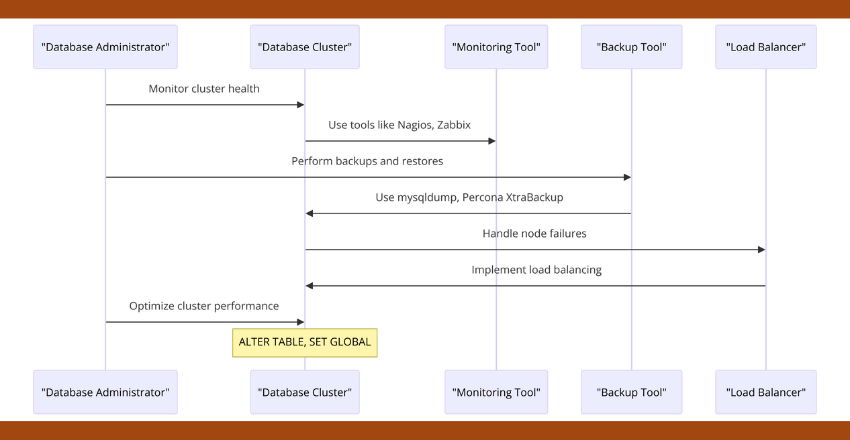
Managing a database cluster is a crucial element in ensuring high availability and optimal performance. Here are some tasks that should be part of your management checklist:
- Monitoring cluster health: Keeping track of the cluster’s overall health is essential in detecting and resolving issues before they escalate. You can use monitoring tools like Nagios, Zabbix, or Datadog to stay on top of your cluster’s performance.
- Performing backups and restores: In case of data loss or corruption, you need to have a solid backup and recovery plan in place. Use tools like mysqldump or Percona XtraBackup to create regular backups that you can restore in case of emergencies.
- Handling node failures: Nodes can fail due to various reasons, like hardware failures or network issues. You need to have a strategy in place to handle node failures and ensure that your cluster remains online. This can be achieved using techniques like automatic failover or manual failover through a load balancer.
- Load balancing: Load balancing helps distribute traffic across your cluster’s nodes, preventing any one node from becoming overloaded. Use tools like NGINX or HAProxy to implement load balancing in your cluster.
- Optimizing cluster performance: You can optimize your cluster’s performance by fine-tuning settings like buffer pools, query caches, and thread pools. SQL code example:
ALTER TABLE mytable ENGINE=INNODB;
SET GLOBAL innodb_buffer_pool_size=4G;
SET GLOBAL query_cache_size=0;
...By following these management practices, you can ensure that your database cluster remains online, performs optimally, and provides high availability even in the face of adversity.
Advantages of Database Clustering

Implementing database clustering can provide numerous advantages for businesses seeking optimal performance, high availability, and efficient data distribution. Here are a few key benefits of database clustering:
- Improved data availability: Clustering allows data to be distributed across multiple nodes, meaning that if one node fails, the others can continue to provide access to the data. This ensures that critical data is always available to users.
- Increased scalability: Clustering allows businesses to easily add new nodes to handle increased traffic or data volume. This means that businesses can easily scale up resources as needed without having to migrate to a different system.
- Enhanced fault tolerance: With multiple nodes, clustered databases can withstand failures, ensuring that business-critical systems continue to operate even during downtime or network outages.
Overall, implementing database clustering can help businesses ensure that they always have access to their critical data, while also allowing them to scale resources as needed and safeguard against failures.
For example, a finance company might use database clustering to ensure that its trading platforms and customer account systems are always available, even in the event of a system failure. Similarly, an e-commerce company might use clustering to ensure that its inventory management and order processing systems are always functional, even during high traffic periods.
If you’re interested in learning more about database clustering and how it can benefit your business, consider hiring dedicated SQL developers from HireSQL. Our team of experienced developers can help you implement database clustering solutions that are tailored to your specific needs.
Challenges and Considerations

While database clustering offers many benefits, it is not without its challenges. One of the primary concerns is network latency, which can slow down data transmission between nodes and affect overall performance. This is especially true for clusters that are geographically dispersed.
Data consistency is another issue that arises when dealing with a distributed environment. Since data is spread across multiple nodes, it is essential to ensure that the data remains consistent across all nodes. Failure to do so can result in data loss or corruption.
The size of the cluster can also impact performance. As the number of nodes in the cluster grows, communication between them becomes more complex, which can lead to latency and decreased performance. Therefore, it is important to carefully consider the number of nodes required for a specific workload.
Strategies for mitigating these challenges include optimizing network performance, implementing proper data replication techniques, and fine-tuning the cluster configuration for optimal performance. These strategies require careful planning and execution, which is why it is essential to work with experienced SQL developers who can help navigate the complexities of database clustering.
Industry Use Cases
Database clustering is becoming increasingly popular across different industries due to its ability to improve high availability, efficient data distribution, and overall performance. Here are some real-world examples of how organizations have leveraged clustering.
Finance
Financial institutions handle large volumes of transactions and need to ensure data is readily available and secure. Database clustering has been instrumental in meeting these requirements. For instance, a leading investment bank utilized Oracle Real Application Clusters (RAC) to improve performance and provide a scalable system for handling transactional workloads.
E-commerce
E-commerce organizations need to manage large databases to keep up with the demand for online shopping. Clustering can help distribute data across multiple nodes and improve the system’s performance. For instance, an online retailer successfully implemented MongoDB clusters to achieve high availability with minimal downtime and ensure a seamless customer experience.
Healthcare
In healthcare, data integrity and availability are critical. Clustering enables providers to store and distribute data across multiple nodes, ensuring efficiency and timely access to critical patient data. For instance, a major healthcare provider utilized SQL Server Always On availability groups to ensure high availability and prevent data loss in case of system failures.
As highlighted by these examples, database clustering has become an essential part of modern database management systems, enabling businesses to achieve high availability, efficient data distribution, and improved performance.
Final Thoughts

Database clustering is a critical concept in modern database management systems. It offers many benefits, including improved performance, high availability, and efficient data distribution.
By understanding the different types of clustering techniques and how to set up and manage a database cluster, organizations can ensure optimal performance and data availability. However, it is essential to consider the challenges that come with clustering, such as network latency and data consistency, and to adopt strategies to mitigate them.
At HireSQL, we provide dedicated SQL developers that can help organizations build, manage and optimize their database clusters. Contact us today to learn more about the benefits of clustering and how we can help.
External Resources
https://learn.microsoft.com/en-us/windows-server/failover-clustering/failover-cluster-csvs
FAQ

1. How do you set up a basic MySQL Cluster for high availability?
FAQ Answer:
Setting up a basic MySQL Cluster involves configuring multiple nodes to work together – typically including at least two data nodes, one management node, and two SQL nodes for high availability. The configuration ensures that the database remains accessible even if one node fails.
Code Sample:
# Config.ini for MySQL Cluster Management Node
[ndbd default]
NoOfReplicas=2 # Number of replicas
[ndbd]
NodeId=2
HostName=datanode1
DataDir=/var/lib/mysql-cluster
[ndbd]
NodeId=3
HostName=datanode2
DataDir=/var/lib/mysql-cluster
[ndb_mgmd]
NodeId=1
HostName=mgmtnode
DataDir=/var/lib/mysql-cluster
[mysqld]
NodeId=4
HostName=sqlnode1
[mysqld]
NodeId=5
HostName=sqlnode2Explanation: This configuration snippet sets up a basic MySQL Cluster with two data nodes for storing the data, one management node to manage the cluster, and two SQL nodes to interface with the cluster. NoOfReplicas=2 ensures high availability by maintaining two copies of the data.
2. What are the key considerations for QA when testing a database cluster for fault tolerance?
FAQ Answer:
QA experts must consider several key factors when testing database clusters for fault tolerance, including simulating node failures, ensuring data integrity during failovers, and verifying that the system meets performance benchmarks under failure conditions.
Code Sample:
# Simulating a node failure in a MySQL Cluster
ndb_mgm> SHOW
# Note the node ID of a data node
ndb_mgm> ENTER SINGLE USER MODE <node_id>
# This command simulates the failure of the specified nodeExplanation: This bash command sequence is used to simulate a node failure in a MySQL Cluster through the management client (ndb_mgm). By putting the cluster into single user mode for a specific node, QA can test how the cluster responds to the node failure, including whether it correctly fails over to another node and maintains data integrity.
3. How do you balance load across nodes in a PostgreSQL cluster for scalability?
FAQ Answer:
Balancing load across nodes in a PostgreSQL cluster typically involves using connection poolers and load balancers to distribute client connections and queries across multiple nodes, ensuring optimal resource utilization and scalability.
Code Sample:
# Example configuration snippet for PgBouncer, a PostgreSQL connection pooler
[databases]
mydb = host=dbnode1 port=5432 dbname=mydb
mydb = host=dbnode2 port=5432 dbname=mydb
[pgbouncer]
listen_port = 6432
listen_addr = *
pool_mode = sessionExplanation: This configuration sets up PgBouncer to listen on port 6432 and distribute connections to the mydb database across two PostgreSQL nodes (dbnode1 and dbnode2). pool_mode = session ensures that a client connection is maintained to the same backend server for the duration of a session, providing a balance between load distribution and transactional integrity.
