







Data Mining leverages sophisticated algorithms to analyze big data, providing a competitive edge by identifying opportunities and optimizing operations.
Data is the currency of the digital age, and businesses of all sizes generate a vast amount of it. However, this data is worthless in its raw form and needs to be analyzed to extract insights. Data mining is a powerful technique that enables businesses to uncover patterns, relationships and hidden insights from large datasets.
Understanding Data Mining
Data mining is a process that involves the extraction of valuable insights from large data sets. It leverages statistical and computational techniques to identify patterns and relationships within the data. Mining techniques are used to uncover previously unknown information and help organizations make data-driven decisions.
Data mining techniques can be categorized into two main types: predictive and descriptive. Predictive techniques use data to make predictions about future events, while descriptive techniques help to understand the current state of affairs. The choice of techniques depends on the objectives of the analysis and the available data.

Six Common Data Mining Techniques
| Technique | Description |
|---|---|
| Clustering | Grouping similar data points together into clusters. |
| Classification | Predicting a categorical outcome based on input variables. |
| Regression | Predicting a numerical outcome based on input variables. |
| Association Rule Mining | Discovering associations among variables in a data set. |
| Neural Networks | Learning a pattern from data and identifying similar patterns in new data. |
| Decision Trees | Dividing data into smaller subsets based on a set of rules. |
SQL is a powerful tool that can be used to implement many of these techniques. For example, clustering can be achieved using the k-Means algorithm in SQL. Similarly, decision trees can be implemented using SQL queries.
By understanding the various mining techniques, data analysts and scientists can decide which technique is most appropriate for their project and can use this knowledge to extract valuable insights from their data.
Data Extraction Methods
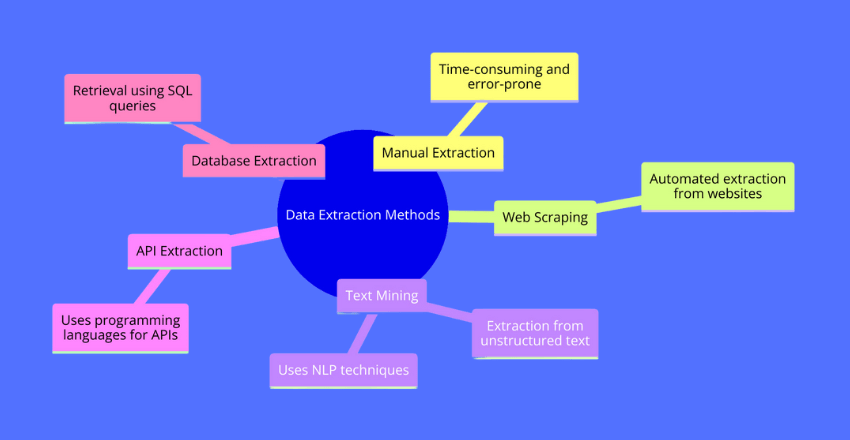
Data extraction is the process of retrieving data from various sources, including databases, websites, and APIs, for further analysis. There are a variety of data extraction techniques and tools available, each with its own strengths and weaknesses.
Manual Extraction
Manual extraction involves the manual entry of data into a system or application. This method is time-consuming and prone to errors, but it can be useful in situations where automated extraction is not possible.
Web Scraping
Web scraping involves the automated extraction of data from websites using web scraping tools or programs. This method is efficient, but it can be legally and ethically questionable if done without permission.
Text Mining
Text mining involves the extraction of data from unstructured text data, such as social media posts and customer reviews. This method uses natural language processing (NLP) techniques to extract meaningful insights from large volumes of unstructured data.
API Extraction
API (Application Programming Interface) extraction involves the use of programming languages to extract data from APIs. This method is efficient and reliable, but it requires a level of technical expertise to implement.
Database Extraction
Database extraction involves the retrieval of data from databases using programming languages and SQL queries. This method is reliable, but it requires a deep understanding of database structures and programming concepts.
In conclusion, data extraction is a crucial step in the data mining process and should be done carefully and thoughtfully. By selecting the appropriate extraction method for a given data source, you can ensure that your data is accurate and relevant for further analysis.
Preparing Data for Analysis
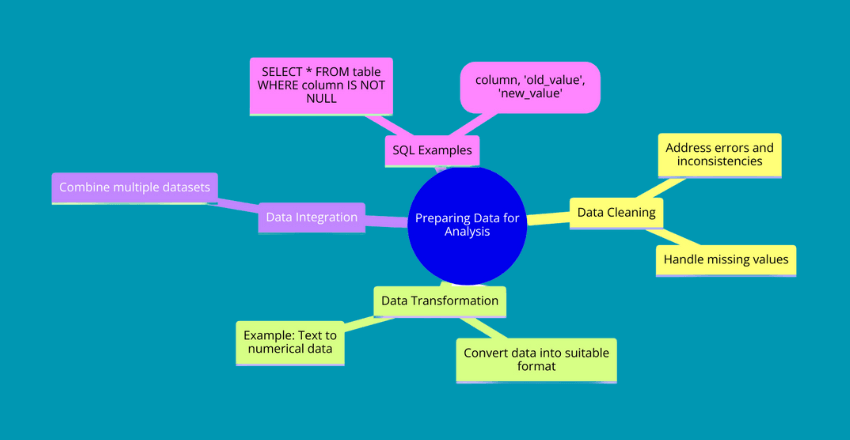
Data preparation is a crucial step in the data mining process, as it ensures that the data is clean, consistent, and in a compatible format for analysis. The following techniques are commonly used in data preparation:
- Data cleaning: This involves identifying and addressing errors, inconsistencies, and missing values in the dataset.
- Data transformation: This involves converting the data into a format that is suitable for analysis. For example, converting text data into numerical data.
- Data integration: This involves combining multiple datasets that are relevant to the analysis.
SQL code can be used to perform data preparation tasks, such as:
SELECT * FROM table WHERE column IS NOT NULL;
UPDATE table SET column = REPLACE(column, 'old_value', 'new_value');By incorporating these techniques, you can ensure that the data used for analysis is accurate and consistent, allowing for more meaningful insights to be extracted using data mining techniques.
Exploratory Data Analysis
Exploratory data analysis techniques are used to discover patterns and relationships within the dataset. This phase of data mining helps to identify issues such as missing values, noisy data, and outliers, which can significantly impact the accuracy of the results.
Techniques utilized in exploratory data analysis include:
- Data visualization: This technique uses graphs and charts to display data in a way that is easy to interpret quickly. Examples include scatter plots, histograms, and box plots.
- Descriptive statistics: This technique helps to summarize the main characteristics of the data, such as mean, median, and standard deviation.
- Dimensionality reduction: This technique reduces the number of variables in the dataset while preserving the main characteristics of the data. Examples include principal component analysis and factor analysis.
Exploratory data analysis is an important step in the data mining process as it helps to identify patterns and relationships that may not be visible through other techniques.
An example of using SQL for data visualization can be seen below:
SELECT product_name, SUM(sales_amount)
AS total_sales FROM sales_data GROUP BY product_name;This SQL code can be used to visualize the total sales for each product in a sales dataset, providing insight into which products are the most profitable.
Supervised Learning Techniques
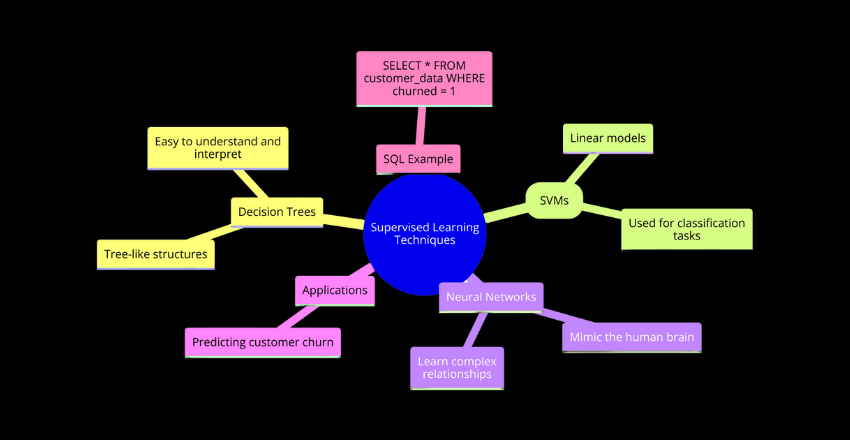
Supervised learning is one of the most popular techniques used in data mining. It involves training a machine learning model on a labeled dataset, where the output is known for each input. The goal is to create a model that can accurately predict the output for new, unseen inputs.
There are several algorithms used in supervised learning, such as decision trees, support vector machines (SVMs), and neural networks. Decision trees are tree-like structures where each node represents a feature or attribute, and the branches represent possible outcomes based on that feature. SVMs are linear models that separate the dataset into two classes using a hyperplane, while neural networks are models that mimic the structure and function of the human brain.
Decision trees are easy to understand and interpret, making them a popular choice for beginners. SVMs are often used for classification tasks, where the goal is to separate the dataset into two or more classes. And neural networks are popular for their ability to learn complex relationships between features.
One example of using supervised learning in data mining is predicting customer churn. By training a model on a labeled dataset of past customers who churned and those who didn’t, the model can predict which customers are at risk of churning in the future.
SQL Code Example:
SELECT * FROM customer_data WHERE churned = 1This SQL code selects all the customers who have churned based on the labeled dataset.
Unsupervised Learning Techniques
Unsupervised learning techniques in data mining are used to discover patterns and relationships within a dataset where no prior knowledge about the outcome or target variable exists.
Clustering is a popular unsupervised learning technique that involves grouping similar data points together based on their features or characteristics. This can provide valuable insights into how data is naturally organized and structured.
Association rule mining is another unsupervised learning technique that focuses on identifying co-occurring patterns in data. This can help in understanding the relationships between different variables and identifying potential areas for further analysis or investigation.
Dimensionality reduction is a technique used to reduce the number of features in a dataset, while still retaining as much information as possible. This can be helpful in simplifying complex datasets and improving the performance of machine learning algorithms.
Overall, unsupervised learning techniques are valuable tools in data mining that can help in uncovering hidden patterns and relationships within large datasets. By applying clustering, association rule mining, or dimensionality reduction techniques, businesses can gain valuable insights into their data that can inform decision-making and improve outcomes.
Evaluating and Interpreting Results

After applying data mining techniques to extract insights, the next step is to evaluate and interpret the results. This involves assessing the performance of the models created and interpreting the findings to identify actionable insights. There are several key techniques and strategies to consider when evaluating and interpreting data mining results.
Performance Measures
Performance measures are used to evaluate the accuracy and effectiveness of the data mining models. Some commonly used measures include precision, recall, accuracy, and F1 score. These measures can be used to identify the strengths and weaknesses of different models, allowing for the selection of the most appropriate model for a given use case.
Model Evaluation Techniques
There are several techniques used to evaluate the performance of data mining models, including cross-validation, holdout validation, and bootstrap validation. Cross-validation involves dividing the dataset into multiple segments and using each segment as both a test and training set. Holdout validation involves dividing the dataset into two separate sets – a training set and a test set – and using these sets to evaluate the model’s performance. Bootstrap validation involves randomly selecting subsets of the dataset to create multiple training and test sets, allowing for the evaluation of model performance across multiple iterations.
Communicating Insights
Effective communication of data mining insights is essential for ensuring that stakeholders can understand and act upon the information provided. This involves presenting findings in a clear and concise manner, using visualizations and other tools to convey complex information. It is also important to tailor the presentation of insights to the needs of the audience, ensuring that the information provided is relevant and actionable.
If you are looking for a dedicated SQL developer to help you extract insights from your data, HireSQL has a team of experienced professionals ready to assist you. With expertise in data mining and other data-related services, we can help you unlock the full potential of your data.
Final Thoughts
Data mining is a powerful tool for extracting insights from big data. By leveraging mining techniques and methodologies, businesses can uncover hidden patterns and relationships that can lead to better decision-making and increased profitability. Understanding the basics of data mining, including data extraction methods, data preparation techniques, exploratory data analysis, supervised and unsupervised learning techniques, and result evaluation, is essential to success.
As a company that provides dedicated SQL Developers speaking English, HireSQL understands the importance of data mining in today’s data-driven world. We encourage readers to apply the knowledge gained from this guide in their own data mining endeavors. By doing so, we are confident that businesses can stay ahead of the competition and achieve their goals.
If you’re interested in learning more about data mining and how HireSQL’s dedicated developers can help your business succeed, get in touch with us today. We are happy to discuss how our team can help you unlock the insights hidden within your data.
External Resources
https://www.ibm.com/topics/supervised-learning
FAQ

1. How do you implement a simple classification model in data mining for predicting customer churn?
FAQ Answer:
Implementing a classification model involves selecting a suitable algorithm (like decision trees, logistic regression, etc.), preparing the dataset (including splitting it into training and testing sets), training the model, and then evaluating its accuracy.
Code Sample: (Using Python and scikit-learn for a Decision Tree Classifier)
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
# Load dataset
data = pd.read_csv('customer_data.csv')
# Prepare data
X = data.drop('Churn', axis=1) # Features
y = data['Churn'] # Target variable
# Split dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize and train classifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
# Predict and evaluate
predictions = classifier.predict(X_test)
print("Accuracy:", accuracy_score(y_test, predictions))Explanation: This code sample demonstrates how to train and evaluate a simple decision tree classifier to predict customer churn. The dataset is split into training and testing sets, with the model trained on the former and evaluated on the latter.
2. What techniques can be used for handling missing data in a dataset before performing data mining?
FAQ Answer:
Handling missing data is crucial for the accuracy of data mining models. Techniques include data imputation, where missing values are replaced with substituted values, and eliminating rows or columns with missing values when appropriate.
Code Sample: (Using Python’s pandas for imputation)
import pandas as pd
from sklearn.impute import SimpleImputer
# Load dataset
data = pd.read_csv('dataset.csv')
# Impute missing values with the mean
imputer = SimpleImputer(strategy='mean')
data_imputed = pd.DataFrame(imputer.fit_transform(data), columns=data.columns)Explanation: This code uses SimpleImputer from sklearn.impute to replace missing values in a dataset with the mean value of each column. It’s a basic but effective method for numerical data imputation.
3. How do you evaluate the performance of a clustering algorithm in data mining?
FAQ Answer:
Evaluating the performance of a clustering algorithm often involves metrics like Silhouette Score or Davies–Bouldin Index, which measure how well data points are clustered together and how distinct the clusters are from each other.
Code Sample: (Using Python and scikit-learn for evaluating K-Means clustering)
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import pandas as pd
# Load dataset
data = pd.read_csv('data.csv')
# Apply clustering
kmeans = KMeans(n_clusters=3, random_state=42).fit(data)
# Evaluate clustering
score = silhouette_score(data, kmeans.labels_)
print("Silhouette Score:", score)Explanation: This code applies K-Means clustering to a dataset and evaluates the clustering performance using the Silhouette Score. A higher Silhouette Score indicates better-defined clusters.
