






As businesses expand and their data needs grow, managing data growth quickly becomes a major challenge. The solution to this challenge is database scalability – ensuring that your database can grow and adapt to changing data needs without sacrificing performance or availability.
Efficient data management strategies are essential for any business looking to achieve database scalability. In this article, we’ll explore different scaling solutions for achieving database scalability and the benefits they offer to businesses. From horizontal and vertical scaling to sharding and replication, we’ll cover all the essential strategies and their pros and cons.
Key Takeaways
- Database scalability is crucial for managing data growth
- Efficient data management strategies are essential for achieving database scalability
- Businesses can use a variety of scaling solutions, including horizontal and vertical scaling, sharding, replication, caching, and database partitioning
Understanding Database Scalability
The explosion in data growth has made database scalability a crucial requirement for businesses today. They need efficient data management strategies to ensure they can manage the ever-increasing amount of data they generate and store. This need has led to the development of scaling solutions that enable databases to handle increasing workloads while maintaining their performance.
As data grows, the challenges it presents to databases become more complex. Databases must be designed to handle not only the growth in data but also the increasing complexity of the data itself. With the help of scaling solutions, businesses can address these challenges and ensure their databases remain reliable and efficient.
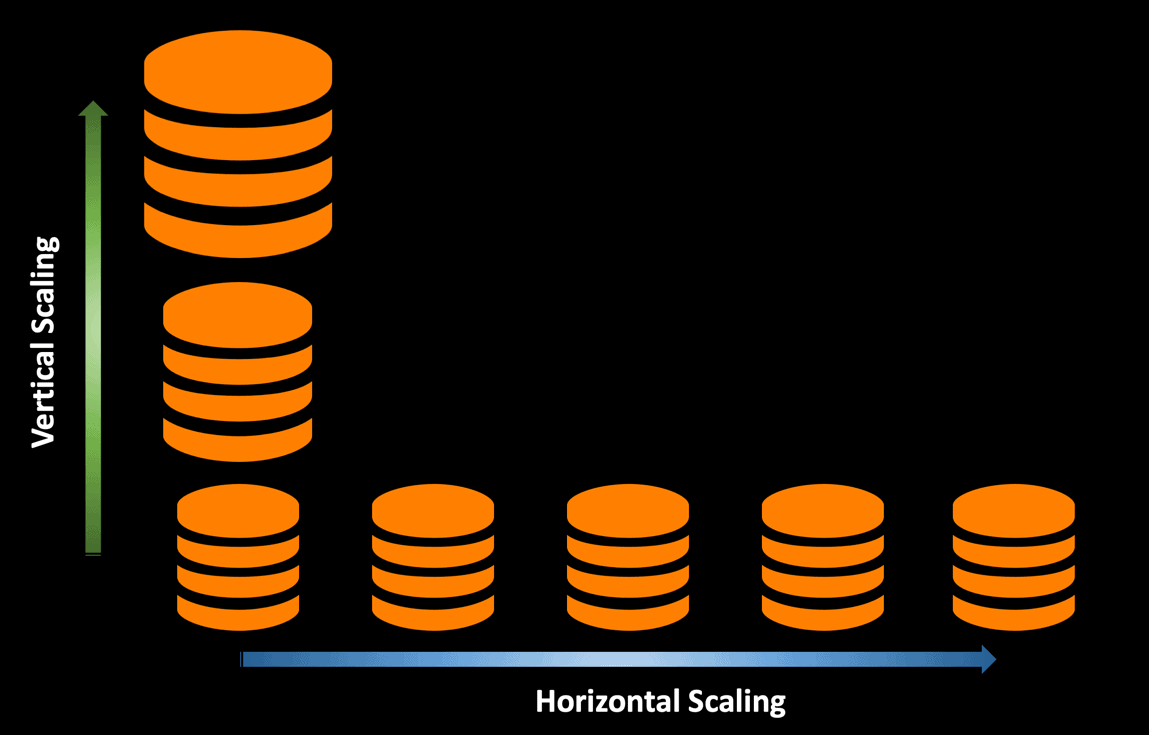
Scaling Strategies for Databases
As businesses continue to accumulate and analyze large volumes of data, it becomes increasingly important to implement efficient data management strategies. Database scalability is a crucial aspect of managing data growth, and there are several scaling strategies that businesses can implement to achieve this.
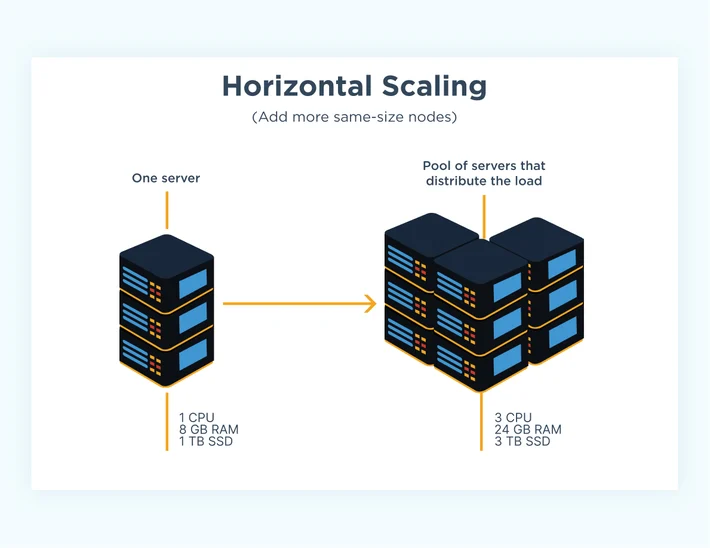
Horizontal Scaling
One common scaling strategy is horizontal scaling, which involves adding more servers to a database to handle increased workloads. This approach enables businesses to distribute the load across multiple servers, providing greater capacity and processing power to handle large volumes of data. Horizontal scaling is often implemented through the use of load balancers, which distribute incoming traffic across multiple servers to ensure that workloads are evenly distributed.
Advantages of horizontal scaling include improved performance and reliability, as well as increased availability. However, this approach can also be more complex to implement and costly, as it requires businesses to add more servers to their infrastructure.
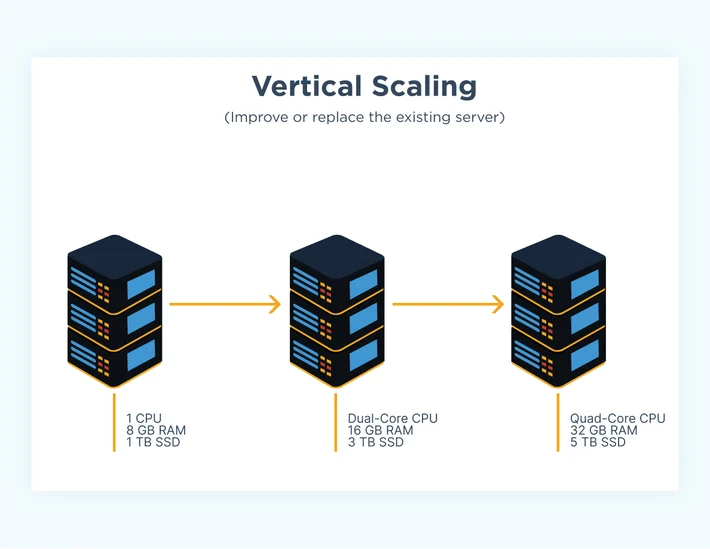
Vertical Scaling
Vertical scaling is another approach to achieving database scalability, which involves increasing the resources of a single server to handle increased workloads. This approach is often used for databases that have limited potential for horizontal scaling, such as those that rely on a single server.
Vertical scaling involves adding more resources such as memory, storage, and processing power to a server to handle more data and user requests. This approach can be more straightforward to implement and less costly than horizontal scaling, but it may not provide the same level of scalability as horizontal scaling.
Sharding
Sharding is a strategy that involves splitting data across multiple servers to improve scalability. This approach enables businesses to divide large datasets into smaller, more manageable fragments, which can be stored and processed on different servers. By doing so, businesses can improve performance and scalability, while also ensuring that data is distributed more evenly across the infrastructure.
Sharding can be particularly effective for databases that experience high levels of traffic or frequent data updates. However, this approach can also add complexity to a database infrastructure, as it requires businesses to manage multiple servers and ensure that data is distributed correctly.
Replication
Replication is another strategy that can help businesses achieve database scalability, which involves creating multiple copies of a database across different servers. This approach enables businesses to distribute workloads across multiple servers, providing greater processing power and redundancy. Replication can be implemented in different ways, such as master-slave replication or multi-master replication, depending on the specific needs of the business.
The advantages of replication include improved performance and availability, as well as greater flexibility and scalability. However, this approach can also require businesses to manage multiple servers and ensure that data is synchronized across the infrastructure.
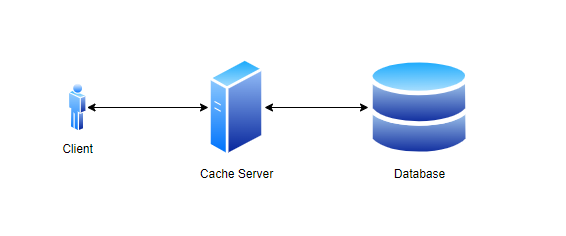
Caching
Caching is a strategy that involves storing frequently accessed data in memory, allowing for faster access and response times. This approach can help businesses improve performance and scalability, as it reduces the amount of time and resources required to retrieve data from a database.
There are different types of caching strategies, such as query caching and application caching, each of which can help businesses optimize their databases for better performance and scalability. However, caching can also increase the complexity of a database infrastructure and require businesses to manage additional layers of caching infrastructure.
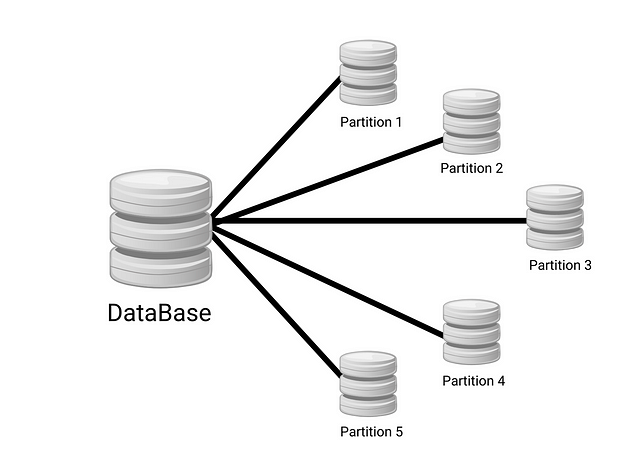
Database Partitioning
Database partitioning is a strategy that involves dividing a database into smaller, more manageable parts, which can be stored and processed on different servers. This approach can help businesses improve scalability, as it enables them to distribute workloads more evenly across the infrastructure, while also improving performance and availability.
Database partitioning can be particularly effective for businesses that have large datasets or experience high levels of traffic. However, this approach can also add complexity to a database infrastructure, as it requires businesses to manage multiple servers and ensure that data is distributed correctly.
How to Implement Database Scalability
Implementing database scalability solutions requires careful planning and execution, and there are several best practices that businesses should follow to ensure success. These include monitoring the performance of the database infrastructure, optimizing the database for better performance, and maintaining the database to ensure its reliability and availability.
Other best practices include choosing the right scaling strategy for the specific needs of the business, ensuring that the database is secure and protected against cyber threats, and providing adequate support and training for IT teams responsible for managing the database infrastructure.
Horizontal Scaling: A SQL Code Example
Below is an SQL code example that demonstrates how to implement a horizontal scaling strategy in a database:
CREATE TABLE customers ( id INT PRIMARY KEY, name VARCHAR(255), email VARCHAR(255), phone VARCHAR(255), address VARCHAR(255) ); CREATE TABLE orders ( id INT PRIMARY KEY, customer_id INT, product_name VARCHAR(255), price DECIMAL(10,2), quantity INT, FOREIGN KEY (customer_id) REFERENCES customers (id) ); CREATE INDEX customer_name ON customers (name); ALTER TABLE orders ADD INDEX customer_id (customer_id);
The code above demonstrates how to create two tables, customers and orders, and add indexes to improve performance. By adding indexes, the database can handle larger volumes of data more efficiently, improving scalability and performance.
Horizontal Scaling
Horizontal scaling is a popular scaling strategy that involves adding more machines or servers to a system to increase its capacity and handle increased workloads. This approach distributes the load across multiple servers, making it easier to manage data growth and maintain optimal performance. Horizontal scaling is particularly useful for high-traffic websites or applications that need to handle a large volume of requests.
The advantages of horizontal scaling include:
- Improved performance and scalability
- Increased fault tolerance and reliability
- Easier to manage and maintain
While horizontal scaling can offer several benefits, it’s important to consider the potential downsides as well. One of the main challenges with horizontal scaling is maintaining consistency and synchronization across multiple machines or servers. This can lead to issues with data integrity and can make it harder to manage complex transactions.
Despite these challenges, horizontal scaling remains a popular and effective way to achieve database scalability. By carefully considering the advantages and limitations of this approach, businesses can implement horizontal scaling successfully and achieve better performance and scalability from their databases.
Vertical Scaling
Vertical scaling involves increasing the resources of a single server to handle increased workloads. This strategy is commonly used for smaller databases that don’t require a large number of servers.
One advantage of vertical scaling is that it is easy to implement. All that is required is to upgrade the capacity of the existing server, such as adding more RAM or CPUs. Additionally, vertical scaling can be more cost-effective than horizontal scaling for smaller databases with lower traffic volumes.
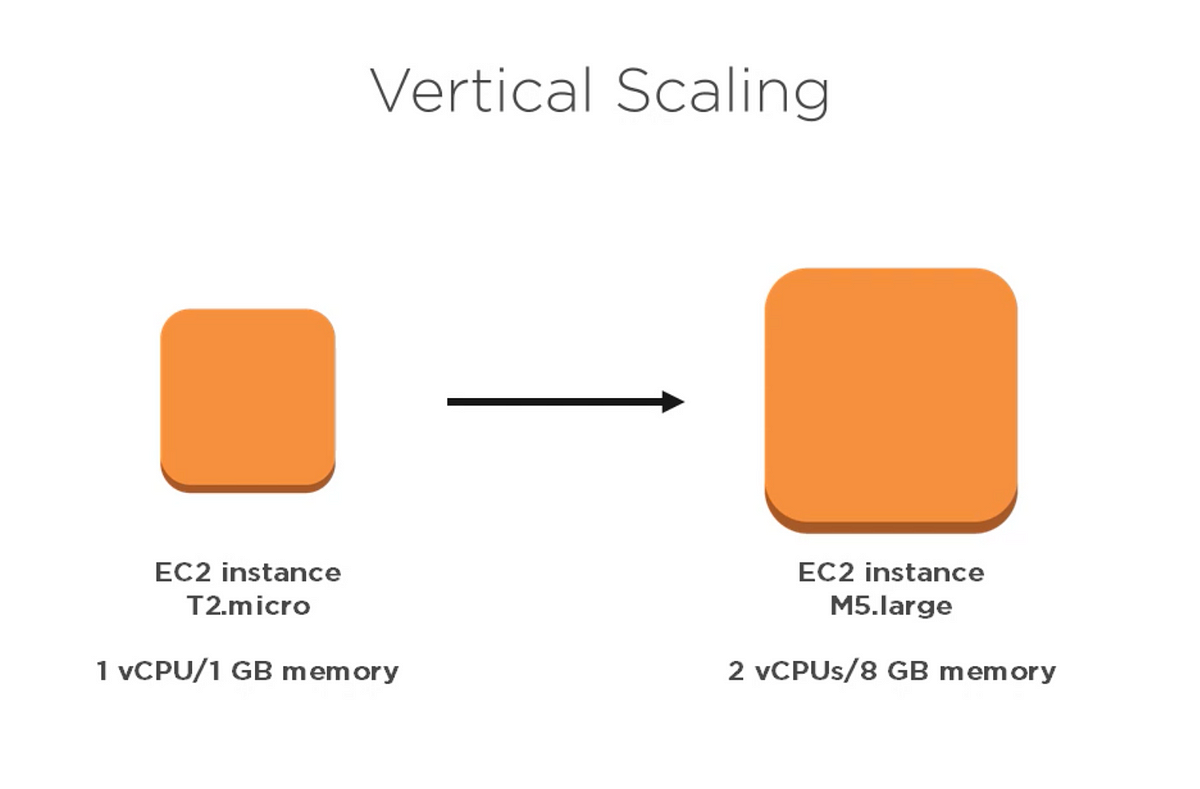
However, there are also limitations to vertical scaling. Eventually, a server will reach its maximum capacity and no further upgrades can be made. This means that vertical scaling may not be suitable for large databases with significant data growth. Additionally, vertical scaling does not offer the same level of redundancy and fault tolerance as other scaling strategies.
Sharding
Sharding is a scaling strategy that involves dividing data across multiple servers. This enables businesses to handle larger amounts of data and traffic without overburdening any single server. Sharding is particularly useful for businesses that need to manage rapidly growing datasets.
One of the main benefits of sharding is that it allows businesses to add new servers as needed, making it highly scalable. Sharding also improves performance by distributing the data across multiple servers, which can reduce the load on any one server.
However, implementing sharding can be complex and requires careful planning to ensure that data is distributed effectively. Additionally, sharding can create performance issues if data is not evenly distributed or if there are frequent queries that rely on data from multiple servers.
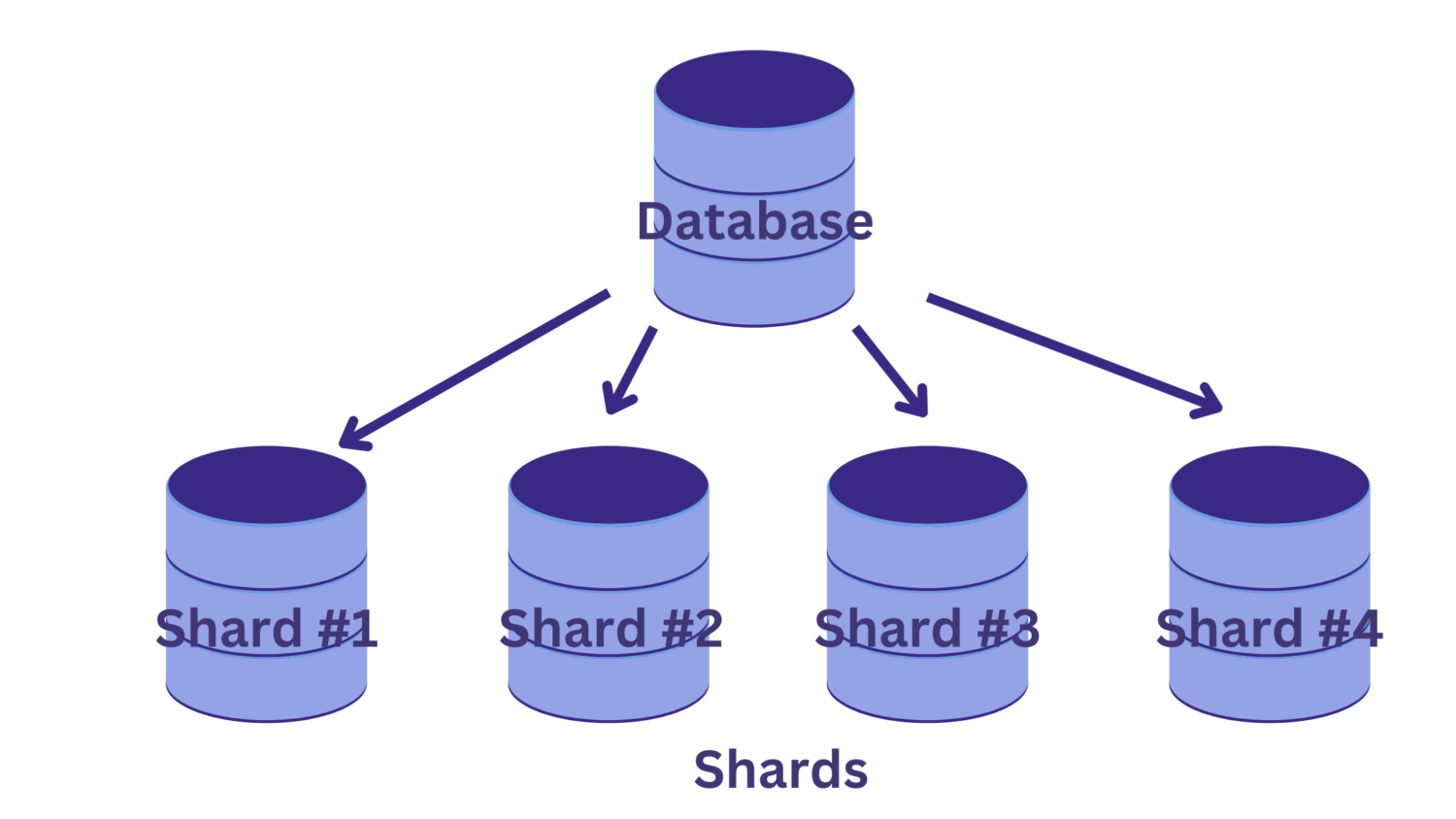
There are several different sharding techniques, including range-based sharding and hash-based sharding. Range-based sharding involves dividing data based on a range of values, such as by date or geographic location. Hash-based sharding involves using an algorithm to distribute data evenly across multiple servers.
Code Example
Here is an example of SQL code for sharding a customer table based on geographic location:
CREATE TABLE customer_usa ( customer_id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50), PRIMARY KEY (customer_id) ) PARTITION BY RANGE (customer_id) (PARTITION customer_region_1 VALUES LESS THAN (100000), PARTITION customer_region_2 VALUES LESS THAN (200000), PARTITION customer_region_3 VALUES LESS THAN (300000), PARTITION customer_region_4 VALUES LESS THAN (MAXVALUE)) ;
This code creates a table called “customer_usa” and partitions it based on the customer_id column. The data is divided into four partitions based on the customer_id value, which corresponds to different geographic regions. By sharding the customer data in this way, businesses can more efficiently manage their data and ensure that queries are run on the appropriate server.
Replication
Replication is a popular strategy for achieving database scalability. It involves creating multiple copies of a database and distributing them across different servers. This strategy ensures that all servers have access to the same data and can process requests independently.
One of the main advantages of replication is its ability to improve database performance. By distributing data across multiple servers, the workload can be evenly spread, reducing the risk of a single server becoming overwhelmed. Additionally, replication can provide redundancy, ensuring that the failure of one server will not result in the loss of data. This improves the availability and reliability of the database.
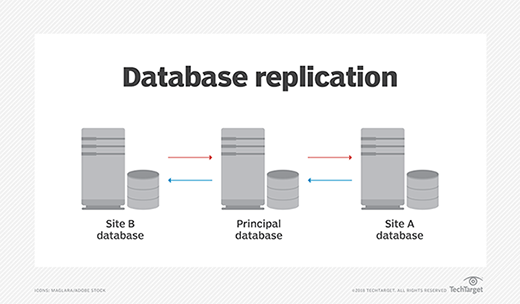
There are two main types of replication: master-slave replication and master-master replication. In master-slave replication, one server (the master) is responsible for performing all write operations, while the other servers (the slaves) copy the data from the master and perform read operations. In master-master replication, all servers can perform both read and write operations, allowing for greater flexibility in managing the workload.
When implementing replication, businesses should consider the potential costs of additional hardware and storage space. Additionally, they should establish a proper synchronization mechanism to ensure that data remains consistent across all servers.
Example: To set up master-slave replication in SQL, you can use the following SQL code:
CREATE TABLE mytable ( id INT NOT NULL AUTO_INCREMENT, name VARCHAR(30) NOT NULL, PRIMARY KEY (id) ); CREATE TRIGGER mytable_trigger AFTER INSERT ON mytable FOR EACH ROW BEGIN INSERT INTO mytable_log (id, name) VALUES (NEW.id, NEW.name); END; CREATE TABLE mytable_log ( id INT NOT NULL AUTO_INCREMENT, name VARCHAR(30) NOT NULL, PRIMARY KEY (id) ); INSERT INTO mytable (name) VALUES ('John'); INSERT INTO mytable (name) VALUES ('Jane');
Replication is a powerful strategy for achieving database scalability, providing benefits such as improved performance, redundancy, and availability. By distributing data across multiple servers, replication can help businesses manage their workloads and ensure that their databases remain responsive and reliable. When implementing replication, businesses should consider the costs and establish proper synchronization mechanisms to ensure data consistency.
Best Practices for Database Scalability

Implementing scalable database systems can be a complex process, but it is essential for managing data growth and ensuring optimal performance. Here are some best practices for scaling strategies that businesses should consider:
- Plan for growth: It’s important to anticipate the growth of your data and plan accordingly. Choose a scalable architecture that can handle increasing volumes of data and traffic.
- Monitor and optimize performance: Regularly monitor database performance and optimize it as needed. Use tools like query optimization, indexing, and caching to improve performance.
- Implement backup and recovery: Ensure that your database is regularly backed up and that there is a disaster recovery plan in place in case of data loss.
- Use proper indexing: Optimize indexing to improve query performance. Use primary keys, foreign keys, and unique indexes where appropriate.
- Choose the right scaling strategy: Evaluate the different scaling strategies and choose the one that best fits your needs. Consider factors like cost, complexity, and performance.
- Consider sharding: Sharding can improve performance and scalability by distributing data across multiple servers. However, be aware of the added complexity and potential performance issues.
- Regularly maintain and upgrade: Regularly maintain your database system and upgrade it to the latest versions to ensure stability, security, and performance.
Database Horizontal Scaling Examples
In order to implement a scaling strategy in your database, you will need to use SQL code to make the necessary changes. Here is an example of SQL code that demonstrates how to implement scaling:
CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(20), hire_date DATE, job_id INT, salary FLOAT, commission_pct FLOAT, manager_id INT, department_id INT );
This SQL code creates a table named “employees” with columns for employee details such as first name, last name, email, phone number, and hire date. The table also includes columns for job ID, salary, commission percentage, manager ID, and department ID.
To implement horizontal scaling, you would need to partition this table into multiple smaller tables based on a shared characteristic, such as an employee’s department. Each partition would be stored on a separate server, allowing for better performance and increased capacity.
Here is an example of SQL code that partitions the “employees” table by department:
CREATE TABLE employees_dept1 ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), phone_number VARCHAR(20), hire_date DATE, job_id INT, salary FLOAT, commission_pct FLOAT, manager_id INT ) PARTITION BY RANGE(department_id) ( PARTITION p0 VALUES LESS THAN (2), PARTITION p1 VALUES LESS THAN (3), PARTITION p2 VALUES LESS THAN (4), PARTITION p3 VALUES LESS THAN (5), PARTITION p4 VALUES LESS THAN (6), PARTITION p5 VALUES LESS THAN (7) );
This SQL code creates six partitions of the “employees” table, with each partition containing employee records for a specific department. By partitioning the data in this way, you can improve query performance for specific departments and manage the data more efficiently.
When implementing any scaling strategy in your database, it is important to test the changes thoroughly before deploying them to your production environment. By following best practices and using SQL code effectively, you can achieve a scalable and efficient database that can support your business needs.
Orders Table Horizontal Sharding Example:
Here is an SQL code example that demonstrates how to implement a horizontal scaling strategy in a database:
CREATE TABLE `orders` ( `order_id` int NOT NULL AUTO_INCREMENT, `customer_id`
int NOT NULL, `order_date` date NOT NULL, `order_total` decimal(10,2) NOT NULL,
PRIMARY KEY (`order_id`), INDEX `customer_idx` (`customer_id`) ) ENGINE=InnoDB;
CREATE TABLE `order_items` ( `item_id` int NOT NULL AUTO_INCREMENT, `order_id`
int NOT NULL, `product_name` varchar(255) NOT NULL, `product_price` decimal(10,2)
NOT NULL, `quantity` int NOT NULL, PRIMARY KEY (`item_id`), INDEX `order_idx`
(`order_id`) ) ENGINE=InnoDB;
CREATE TABLE `customers` ( `customer_id` int NOT NULL AUTO_INCREMENT,
`first_name` varchar(50) NOT NULL, `last_name` varchar(50) NOT NULL,
`email` varchar(255) NOT NULL, PRIMARY KEY (`customer_id`) ) ENGINE=InnoDB;
ALTER TABLE `orders` ADD COLUMN `shard_id` int NOT NULL DEFAULT 0,
ADD INDEX `shard_idx` (`shard_id`);
ALTER TABLE `order_items` ADD COLUMN `shard_id` int NOT NULL DEFAULT 0,
ADD INDEX `shard_idx` (`shard_id`);
ALTER TABLE `customers` ADD COLUMN `shard_id` int NOT NULL DEFAULT 0,
ADD INDEX `shard_idx` (`shard_id`);This code sets up a database with three tables: orders, order_items, and customers. To implement horizontal scaling, a shard_id column is added to each table, and an index is created on the shard_id column. Then, each shard is placed on a separate server, allowing the database to handle increased workloads.
Overall, implementing database scalability solutions is critical for businesses to manage data growth and maintain optimal database performance. By choosing the right scaling strategy and implementing best practices, businesses can ensure that their databases are scalable and can handle future growth.
As Data Grows
As data grows exponentially, databases must be able to scale efficiently to meet the demand. Implementing scaling solutions is crucial to managing data growth and ensuring the optimal performance of databases.
Businesses can achieve database scalability through various strategies including horizontal scaling, vertical scaling, sharding, replication, caching, and database partitioning. Each strategy has its advantages and limitations, and it is essential to choose the right approach for the specific use case and business requirements.
Best practices for implementing database scalability solutions include monitoring and optimizing database performance, planning for future growth, and maintaining data consistency and integrity.

FAQ
Q: What is database scalability?
A: Database scalability refers to the ability of a database to handle increased workloads and data growth efficiently. It involves implementing strategies and technologies that allow databases to scale and accommodate growing data demands.
Q: Why is database scalability important?
A: Database scalability is important because it ensures that a database can effectively manage data growth and handle increased workloads. Without scalability, databases can become overwhelmed, leading to performance issues, slower response times, and potential data loss.
Q: What are scaling strategies for databases?
A: Scaling strategies for databases are approaches businesses can implement to achieve database scalability. These strategies involve techniques such as horizontal scaling, vertical scaling, sharding, replication, caching, and database partitioning.
Q: What is horizontal scaling?
A: Horizontal scaling is a database scaling strategy that involves adding more servers to distribute the workload across multiple machines. It allows databases to handle increased data demands by scaling out rather than scaling up.
Q: What is vertical scaling?
A: Vertical scaling is a database scaling strategy that involves increasing the resources of a single server, such as adding more CPU, RAM, or storage capacity. It allows databases to handle increased workloads by scaling up the existing server.
Q: What is sharding?
A: Sharding is a database scaling strategy that involves dividing data across multiple servers or shards. Each shard contains a subset of the total data, allowing for increased scalability and performance.
Q: What is replication?
A: Replication is a database scaling strategy that involves creating copies of a database and distributing them across multiple servers. It allows for increased read capacity, fault tolerance, and data availability.
Q: What is caching?
A: Caching is a technique used to improve database scalability by storing frequently accessed data in a high-speed cache. It reduces the need to query the database for the same data repeatedly, improving performance and reducing the load on the database.
Q: What is database partitioning?
A: Database partitioning is a strategy for achieving database scalability by dividing a database into smaller, more manageable parts called partitions. Each partition can be stored and processed independently, improving performance and scalability.
Q: What are the best practices for database scalability?
A: When implementing database scalability solutions, it is important to follow certain best practices. These include regularly monitoring the database’s performance, optimizing queries and indexes, implementing proper backup and recovery strategies, and staying up to date with security patches and upgrades.
Q: Can you provide an SQL code example for implementing database scalability?
A: Sure! Here’s an example of how to implement horizontal scaling in an SQL database:
CREATE TABLE customers (
id INT PRIMARY KEY,
name VARCHAR(50),
email VARCHAR(50)
);With horizontal scaling, you can distribute this table across multiple servers to handle increased workloads.
External References
How sharding a database can make it faster – https://stackoverflow.blog/2022/03/14/how-sharding-a-database-can-make-it-faster/
Database Scaling Strategies – https://www.linkedin.com/pulse/database-scaling-strategies-ran-bechor
Horizontal and Vertical Scaling In Databases – https://www.geeksforgeeks.org/horizontal-and-vertical-scaling-in-databases/
Sarah is an accomplished author, esteemed for her expertise in the field of data science and her engaging written works that cater specifically to the data industry. Residing in the vibrant city of London, she embarked on an academic journey at Cambridge University, where she immersed herself in the world of mathematics. This foundational education formed the bedrock of her illustrious career.
Driven by a desire to broaden her horizons, Sarah sought new challenges and opportunities, leading her to embrace a pivotal role at NetApp, a renowned data storage consultancy firm. In this capacity, she thrived in the dynamic landscape of data architecture, devising innovative strategies to optimize data storage, retrieval, and management for a diverse range of clients. Sarah’s intricate understanding of the intricacies of data systems and her ability to craft tailor-made solutions earned her accolades and solidified her reputation as a sought-after industry expert.
Beyond her professional pursuits, Sarah gracefully balances her roles as a devoted mother and an accomplished equestrian. She finds immeasurable joy in nurturing her daughter, guiding her through the intricacies of life, and instilling a love for knowledge and creativity. Sarah’s dedication to both her family and her career exemplifies her unwavering commitment to excellence in all facets of life.
