






SQLAlchemy and BigQuery enable developers to efficiently manage and query massive datasets, leveraging Python’s flexibility for advanced data engineering.
If you’re a developer looking for efficient ways to manage data, you’re probably already familiar with tools like SQLAlchemy and BigQuery. But if you’re not sure how to leverage them to their fullest potential, you’re missing out on key opportunities to streamline your database integration and management process.
SQLAlchemy is an open-source SQL toolkit and Object-Relational Mapping (ORM) library for Python. It provides a set of high-level API for connecting to various relational databases such as MySQL, PostgreSQL, and Oracle. On the other hand, BigQuery is a powerful serverless data warehousing and analytics platform by Google Cloud.
It allows you to store, manage, and query massive datasets using SQL-like syntax.
Together, SQLAlchemy and BigQuery offer developers a robust set of capabilities for managing data. Whether you’re building an application that requires fast, scalable storage or working with big data, these tools can help you optimize your workflow and improve the performance of your applications.
Leveraging SQLAlchemy for Python SQL Tools
SQLAlchemy is a powerful SQL toolkit and Object Relational Mapping (ORM) library for Python. It provides a set of high-level API to simplify the process of SQL database integration and management.
One of the essential features of SQLAlchemy is its flexibility and portability. It supports a wide range of SQL databases, including PostgreSQL, MySQL, Oracle, and SQLite, among others. This makes it an attractive option for developers who need to work with multiple database systems.

SQLAlchemy also provides a comprehensive set of SQL expressions, functions, and query builders to simplify the creation and execution of SQL statements. These tools are designed to be intuitive and easy to use for developers of all skill levels.
This is due to its unique features and capabilities, including:
| Feature | Description |
|---|---|
| ORM Integration | SQLAlchemy seamlessly integrates with popular Python ORM libraries such as Django ORM and Flask SQLAlchemy, providing a higher level of abstraction to the SQL database functionality. |
| Dynamic SQL Expressions | SQLAlchemy supports dynamic SQL expressions, allowing developers to build complex SQL queries using Python code. This ensures that the resulting SQL is secure and less error-prone compared to static SQL. |
| Query Builder | SQLAlchemy provides a query builder that allows developers to create SQL queries programmatically, eliminating the need for writing raw SQL code. |
Developers can leverage these features to create powerful SQL tools that simplify database integration and management. For example, SQLAlchemy can be used to create Python-based data analysis tools, ETL (Extract, Transform, Load) frameworks, and data visualization applications.
Here is an example of how SQLAlchemy can be used to query a MySQL database in Python:
from sqlalchemy import create_engine, MetaData, Table, select
engine = create_engine('mysql://user:password@host:port/database')
connection = engine.connect()
metadata = MetaData()
users = Table('users', metadata, autoload=True, autoload_with=engine)
stmt = select([users.c.id, users.c.name])
result = connection.execute(stmt)
for row in result:
print(row)This code uses SQLAlchemy to query a MySQL database and retrieve the ‘id’ and ‘name’ columns from the ‘users’ table.
Understanding BigQuery: A Powerful Database Integration
BigQuery is a fully-managed, cloud-native data warehouse that enables developers to store, manage, and query large datasets with ease. As a highly scalable and flexible platform, BigQuery is ideal for integrating with various data sources and performing complex analytics tasks.
One of the key advantages of BigQuery is its seamless integration with other Google Cloud services like Dataproc and Cloud Storage. This enables developers to ingest and process data from a wide range of sources, including structured and unstructured data, with a high degree of efficiency and reliability.
BigQuery’s architecture is designed to handle complex queries and large datasets efficiently. It uses a distributed SQL-like query language called Standard SQL, which supports a wide range of SQL functions and operators for performing advanced data analysis.
| Key Features of BigQuery | Benefits for Developers |
|---|---|
| Scalable and flexible platform | Allows handling of large datasets easily |
| Integration with Google Cloud services | Allows for efficient data ingestion and processing from multiple sources |
| Distributed SQL-like query language | Supports advanced data analysis functions and operators for querying complex datasets |
Using BigQuery, developers can choose from a variety of data ingestion options, including streaming data, batch processing, and data transfer services. This flexibility makes it easy to integrate data from a wide range of sources into BigQuery for analysis and reporting.
Overall, BigQuery offers a powerful and highly scalable platform for database integration, making it an ideal choice for developers working with large and complex datasets.
Benefits of Using SQLAlchemy with BigQuery

Combining SQLAlchemy and BigQuery offers a range of benefits, making it an ideal choice for developers who want to manage data effectively. Here are some key advantages of using SQLAlchemy with BigQuery:
| Advantages | Explanation |
|---|---|
| Flexibility | With SQLAlchemy, developers can use a single API to connect to multiple databases. This makes it easier to switch between databases and work with different data sources. Additionally, BigQuery’s cloud-based infrastructure allows for easy scalability and efficient data management. |
| Integration | Integrating SQLAlchemy with BigQuery helps to simplify the development process. SQLAlchemy provides a straightforward way to connect with BigQuery, enabling developers to work with data in a fast, reliable, and efficient manner. |
| Query Optimization | SQLAlchemy provides developers with a range of tools to optimize queries. This helps to improve query speed and performance, reducing the time it takes to retrieve data from BigQuery. |
| Data Modeling | With SQLAlchemy, developers can easily create data models that work with BigQuery. This helps to ensure that the data is structured correctly, making it easier to query and analyze data. |
These are just a few examples of the benefits that come with using SQLAlchemy and BigQuery together. The combination of these two powerful tools helps developers to manage data efficiently and effectively, reducing development time and costs.
Code Example:
# Importing necessary libraries
from sqlalchemy import create_engine, MetaData, Table, select
# Connecting to BigQuery using SQLAlchemy
engine = create_engine('bigquery://project_id')
# Creating metadata object
metadata = MetaData(engine)
# Creating table object
table = Table('table_name', metadata, autoload=True)
# Creating query object
query = select([table])
# Executing the query and printing the result
result = engine.execute(query)
print(result.fetchall())In this code example, we use SQLAlchemy to connect to BigQuery and fetch data from a table. Using SQLAlchemy, developers can leverage the power of BigQuery’s cloud-based infrastructure and efficient query processing to manage and analyze large datasets effectively.
Getting Started with SQLAlchemy and BigQuery
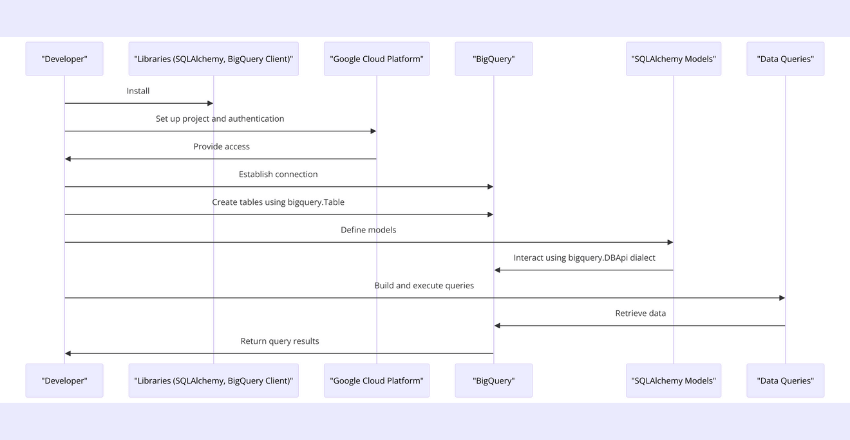
If you are a developer looking to leverage the power of SQLAlchemy and BigQuery for efficient data management, here’s how you can get started:
- Install the required libraries: You will need to install the latest versions of SQLAlchemy and the Google Cloud BigQuery Python client library.
- Project Setup: Create a new project in the Google Cloud Console and set up authentication. Ensure that you have the necessary permissions to access BigQuery.
- Connect to BigQuery: Once your project is set up, you can establish a connection to BigQuery by creating a new instance of the `bigquery.Client` class and passing in your project ID.
- Create Tables: You can create tables in BigQuery using the `bigquery.Table` class.
- Create Models: Use SQLAlchemy to define your data models and interact with BigQuery. The `bigquery.DBApi` dialect allows you to use SQLAlchemy with BigQuery.
- Query Data: Use SQL queries to retrieve data from BigQuery. You can use SQLAlchemy to build queries and execute them using the `execute()` method.
Here is an example of how to create a model:
# Define the model class
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
position = Column(String)
# Create the table in BigQuery
from google.cloud import bigquery
client = bigquery.Client()
table_id = "project_id.dataset_id.employee"
schema = [bigquery.SchemaField("id", "INTEGER", mode="REQUIRED"), bigquery.SchemaField("name", "STRING", mode="NULLABLE"), bigquery.SchemaField("address", "STRING", mode="NULLABLE"), bigquery.SchemaField("position", "STRING", mode="NULLABLE")]
table = bigquery.Table(table_id, schema=schema)
table = client.create_table(table) # API requestOnce you have set up your project and established a connection to BigQuery, you can use SQLAlchemy to interact with your data and build powerful applications.
Best Practices for SQLAlchemy and BigQuery Integration

Integrating SQLAlchemy and BigQuery can help developers better manage their data. Implementing best practices for this integration can help optimize performance and improve efficiency. Here are some tips:
Data Modeling
Effective data modeling is key to efficient data management. Use SQLAlchemy’s Object Relational Mapping (ORM) to map database tables to Python classes. This simplifies code and makes querying data easier. Use BigQuery’s Schema auto-detection feature to automatically generate table schemas based on data being uploaded.
Query Optimization
Limit the number of columns being queried to only those that are necessary. Avoid using SELECT * in SQL queries. Use SQLAlchemy’s Query API to efficiently write and execute SQL statements. Consider using BigQuery’s cache feature to speed up frequently used queries.
Performance Tuning
Monitor and analyze query performance regularly. Use SQLAlchemy’s built-in profiler to identify bottlenecks and optimize code. Consider using BigQuery’s error logging to identify and fix issues in your queries.
Security
Keep your data and credentials secure by using encryption and authorization techniques. Use SQLAlchemy’s database authentication methods to enforce access controls and prevent unauthorized data access. Use BigQuery’s IAM feature to manage permissions and grant access to specific resources.
Code Reusability
Make your code easily reusable by encapsulating it into libraries and functions. Use SQLAlchemy’s query generation library, SQLalchemy-Utils, to build reusable, composable query constructs. Consider using BigQuery’s Command Line Interface (CLI) or API to automate tasks and streamline workflows.
Testing and Maintenance
Test your code regularly to identify and fix issues before they cause problems. Use SQLAlchemy’s testing utilities to create unit tests and integration tests. Use BigQuery’s unit testing framework to test queries and functions. Regularly maintain your code by updating libraries and dependencies.
By following these best practices, developers can effectively integrate SQLAlchemy and BigQuery for efficient data management and improved performance.
Advanced Techniques for SQLAlchemy and BigQuery
While the basics of using SQLAlchemy with BigQuery can greatly improve your data management, there are also many advanced techniques that can take your development to the next level.
One such technique is data streaming, which allows developers to continuously write data to BigQuery tables in real-time. This can be achieved by using the BigQuery streaming API in conjunction with SQLAlchemy, enabling developers to handle large and constantly changing datasets.
Another advanced technique involves schema management, which can be especially useful when handling complex datasets. SQLAlchemy provides a powerful ORM system capable of automatically creating and managing database schemas, making it easier for developers to make changes and updates to their datasets.
Finally, performance tuning is an important aspect of integrating SQLAlchemy and BigQuery effectively. By optimizing queries and properly structuring data, developers can ensure that their applications run smoothly and efficiently.
Example:
Here’s an example of using SQLAlchemy to stream data into a BigQuery table:
from google.cloud import bigquery
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData
client = bigquery.Client()
engine = create_engine('bigquery://my-project')
metadata = MetaData()
table = Table('my_table', metadata,
Column('id', Integer),
Column('name', String(50)),
Column('age', Integer))
metadata.create_all(engine)
with engine.connect() as conn:
for i in range(10):
conn.execute(table.insert().values(id=i, name='John', age=30))By utilizing advanced techniques like these, developers can take full advantage of the power and flexibility of SQLAlchemy and BigQuery, and unlock new possibilities for data management and analysis.
Troubleshooting and Tips for SQLAlchemy and BigQuery
While using SQLAlchemy and BigQuery together can provide a powerful toolset for managing data, there may be some challenges that developers face. Here are some common issues and troubleshooting tips:
Connection Errors
If you encounter any connection errors while using SQLAlchemy and BigQuery, check that your credentials are correct and that the necessary libraries are installed. Additionally, ensure that your firewall is not blocking the connection.
Performance Issues
Large datasets can sometimes cause performance issues when working with SQLAlchemy and BigQuery. To optimize performance, try using partitioned tables and query only the necessary columns. You can also consider using caching mechanisms to reduce the number of queries.
Data Types
When using SQLAlchemy with BigQuery, be aware of any data type inconsistencies between the two platforms. For example, BigQuery uses a TIMESTAMP data type, while SQLAlchemy uses a DATETIME data type. Ensure that your data types are compatible to avoid any errors.
Final Thoughts about SQLAlchemy and BigQuery

Effective data management is critical for any organization. With the rise of big data, it has become even more crucial to have reliable and efficient tools to manage and analyze data. SQLAlchemy and BigQuery are two powerful tools that can help developers achieve this objective.
By leveraging the capabilities of SQLAlchemy, developers can simplify database integration and manage SQL tools in Python effectively. BigQuery, on the other hand, provides a scalable and flexible cloud-based solution for data warehousing and analysis. When combined, these two tools can offer significant advantages for organizations looking to streamline their data management processes.
When integrating and using these tools, there are best practices and advanced techniques that developers should be aware of to optimize their performance. It is also important to troubleshoot common issues and stay up-to-date with the latest trends and developments in the field.
At HireSQL, we understand the importance of efficient data management and the value of these powerful tools. Our dedicated SQL developers are well-versed in SQLalchemy and BigQuery and can help organizations harness their power to achieve their data management goals.
Take advantage of the power of SQLAlchemy and BigQuery today and explore the endless possibilities for efficient data management.
External Resources
https://cloud.google.com/bigquery
FAQ

Quality assurance (QA) experts often face challenges when integrating and testing applications that interact with databases, especially with advanced tools like SQLAlchemy for ORM (Object-Relational Mapping) and Google BigQuery for big data analytics. Here are three frequently asked questions (FAQs) with answers, code samples, and explanations focused on “SQLAlchemy and BigQuery”:
1. How can you connect SQLAlchemy to BigQuery to perform data operations?
FAQ Answer:
To connect SQLAlchemy to BigQuery, you need to use the sqlalchemy-bigquery library, which allows SQLAlchemy to communicate with BigQuery through its dialect. This setup enables you to perform data operations on BigQuery using SQLAlchemy’s ORM capabilities.
Code Sample:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# Replace YOUR_PROJECT_ID with your actual Google Cloud project ID
connection_string = "bigquery://YOUR_PROJECT_ID"
# Create an engine instance
engine = create_engine(connection_string)
# Create a Session
Session = sessionmaker(bind=engine)
session = Session()
# Now you can use session to perform data operationsExplanation: This code snippet demonstrates how to set up a connection to BigQuery using SQLAlchemy. It creates an engine that communicates with BigQuery using the project ID and initializes a session through which you can execute queries and data operations.
2. How do you execute a query on BigQuery using SQLAlchemy and handle the results?
FAQ Answer:
Executing a query on BigQuery using SQLAlchemy involves creating a session and using the session to execute raw SQL queries or utilizing the ORM capabilities to interact with the database in a more Pythonic way. Handling results typically involves iterating over the result set returned by the query.
Code Sample:
# Assuming the engine and session have been set up as before
query = "SELECT * FROM your_dataset.your_table WHERE conditions = 'value'"
# Execute the query and fetch results
result = session.execute(query)
for row in result:
print(row) # Each row is a tuple of column valuesExplanation: This code snippet shows how to execute a raw SQL query against BigQuery through a SQLAlchemy session and iterate over the results. Each row in the result set is accessible in a Pythonic manner, allowing for easy data manipulation and analysis.
3. How can you use SQLAlchemy models to interact with BigQuery tables?
FAQ Answer:
Using SQLAlchemy models to interact with BigQuery tables involves defining models that reflect the structure of your BigQuery tables. Once defined, you can use these models to perform CRUD (Create, Read, Update, Delete) operations in an object-oriented manner.
Code Sample:
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, String, Integer
Base = declarative_base()
class User(Base):
__tablename__ = 'users' # Name of the table in BigQuery
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
# Assuming the session has been created as shown earlier
# To add a new user
new_user = User(id=1, name='John Doe', email='john@example.com')
session.add(new_user)
session.commit()
# Query users
users = session.query(User).filter_by(name='John Doe').all()
for user in users:
print(user.id, user.name, user.email)Explanation: This code defines a User model that corresponds to a users table in BigQuery. It demonstrates how to add a new user to the table and how to query users by name. Using SQLAlchemy models provides an abstraction layer that simplifies interactions with BigQuery tables by allowing developers to work with Python objects rather than raw SQL queries.
