







Database Design Principles: Navigate the Complex World of Data Architecture with Proven Techniques for Ensuring Consistency and Accessibility.
Effective database design is essential for improving performance, scalability, and data integrity. Whether you are a seasoned SQL developer or a newcomer to database design, following design principles can help you design databases efficiently and effectively.
Database Schema

A database schema is like the blueprint for a house. It outlines the structure of how data will be stored and organized within a database. A well-designed schema is essential for a properly functioning database, which is why it’s important to understand its purpose and how to create one.
The schema defines the tables, columns, relationships, and constraints of a database. By defining these aspects, the schema ensures consistency and accuracy in the data that is stored. The schema also makes it easier to retrieve specific data and perform complex queries.
When designing a schema, it’s important to consider the future growth of the database. This means anticipating the types of data that may need to be stored in the future and designing the schema accordingly.
Additionally, it’s important to follow best practices when designing a schema. This includes defining primary and foreign keys, avoiding redundancy, and normalizing the data. A normalized database ensures that data is stored efficiently and avoids duplicating information. This approach helps to reduce data storage requirements and improve query performance.
Example of a basic schema:
| User | Order |
|---|---|
|
|
In the example schema above, there are two tables: User and Order. The User table has a primary key, User_ID, and the Order table has a primary key, Order_ID. The Order table also has foreign keys, User_ID and Product_ID, which reference the primary keys of the User and Product tables.
Another Example Database Schema: Online Bookstore
Overview
This schema example is for an online bookstore. It includes tables for Books, Authors, Customers, and Orders. The schema is designed to efficiently store and manage data regarding book inventory, author details, customer information, and purchase orders.
Schema Design
- Books Table
- Stores information about each book.
- Fields:
BookID(Primary Key),Title,AuthorID(Foreign Key),Genre,Price,PublishDate. - Ensures easy retrieval of book details and categorization.
CREATE TABLE Books (
BookID INT PRIMARY KEY,
Title VARCHAR(255),
AuthorID INT,
Genre VARCHAR(100),
Price DECIMAL(10, 2),
PublishDate DATE,
FOREIGN KEY (AuthorID) REFERENCES Authors(AuthorID)
);Authors Table
- Contains details about authors.
- Fields:
AuthorID(Primary Key),Name,Bio,Country. - Facilitates storing comprehensive information about the authors of the books.
CREATE TABLE Authors (
AuthorID INT PRIMARY KEY,
Name VARCHAR(100),
Bio TEXT,
Country VARCHAR(50)
);Customers Table
- Records customer information.
- Fields:
CustomerID(Primary Key),Name,Email,Address,JoinDate. - Supports maintaining a record of customers for communication and marketing.
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
Name VARCHAR(100),
Email VARCHAR(100),
Address TEXT,
JoinDate DATE
);Orders Table
- Logs each purchase order.
- Fields:
OrderID(Primary Key),CustomerID(Foreign Key),BookID(Foreign Key),OrderDate,Quantity,TotalPrice. - Links
Customersto their purchasedBooks, facilitating order tracking and management.
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
BookID INT,
OrderDate DATE,
Quantity INT,
TotalPrice DECIMAL(10, 2),
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID),
FOREIGN KEY (BookID) REFERENCES Books(BookID)
);Design Considerations
- Normalization: This schema is designed to avoid redundancy. Each table focuses on a single aspect (e.g., books, authors), reducing duplicate data storage.
- Future Growth: The schema allows for easy addition of new tables or columns (e.g.,
Publishers,Reviews) to accommodate future expansion. - Primary and Foreign Keys: The use of primary and foreign keys enforces data integrity and establishes relationships between tables.
This database schema for an online bookstore illustrates the application of best practices in schema design, including considerations for normalization, data integrity, and scalability. By adhering to these principles, the schema ensures efficient data storage, retrieval, and management, supporting the operational needs of the online bookstore.
By understanding how to design a database schema, you can create a well-organized and efficient database that meets the needs of your organization.

Identifying Business Requirements
When it comes to designing efficient databases, it’s crucial to start with a clear understanding of the business requirements. This involves identifying the needs and goals of the organization, as well as the data that will be stored and managed within the database.
By taking the time to gather and analyze this information, database designers can ensure that they create a database that meets the specific needs of the organization. This, in turn, can lead to improved efficiency and effectiveness.
One important aspect of identifying business requirements is determining the relationships between different pieces of data. This can help designers create a logical schema for the database, which is crucial for efficient and effective data management.
Another key consideration is identifying any potential constraints or limitations that may impact the design of the database. This could include factors such as the amount of storage available, the expected volume of data, or any legal or regulatory requirements that must be followed.
Example SQL Code:
SELECT * FROM customers WHERE country = 'USA';Overall, following design principles and taking the time to identify business requirements is crucial for developing databases that are efficient, effective, and meet the specific needs of the organization.
Normalization for Data Integrity
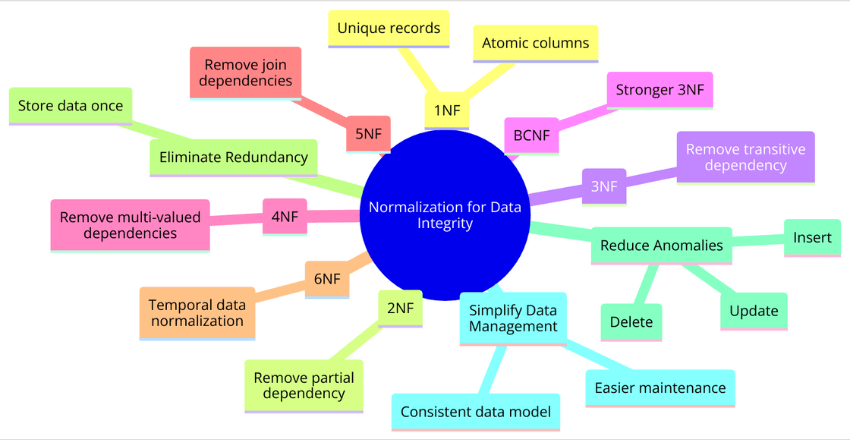
Normalization is a critical design principle that helps ensure data integrity in a relational database. It involves organizing data into tables and establishing relationships between them, based on their dependencies and characteristics.
The goal of normalization is to eliminate data redundancy, reduce data anomalies, and simplify data management. It is achieved by breaking down data into smaller, more manageable units, or “normal forms,” each with its own unique set of attributes and relationships.
There are several normal forms, ranging from first normal form (1NF) to sixth normal form (6NF), each with its own specific criteria and benefits. The higher the normal form, the more normalized and efficient the database design is.
By applying normalization, you can ensure that each data item is stored only once and that all related data is stored together. This prevents inconsistencies and inaccuracies that could arise from duplicated or conflicting data.
For example, suppose you have a table that stores customer information, including their name and address. If each customer has multiple orders, instead of storing all order information in the same table, you could create a separate table for orders and link it to the customer table through a unique identifier, such as customer ID. This way, you would avoid duplicating customer information in each order record, which would lead to data redundancy and inconsistency.
Below is an example of how normalization can be applied to a database:
| Table Name | Description |
|---|---|
| Employees | Stores employee information |
| Departments | Stores department information |
| Employee_Department | Stores the relationship between employees and departments |
By separating the employee and department information into different tables and linking them through a relationship table, you can ensure that each employee is associated with only one department, regardless of how many employees or departments there are. This simplifies data management and reduces redundant data.
Overall, normalization is a key design principle that ensures data integrity, consistency, and efficiency in a relational database. By following best practices and applying the appropriate normal forms, you can create a well-organized, scalable database that meets your business needs.
Indexing for Performance Optimization
Designing an efficient database involves many factors, one of which is indexing. Indexing is the process of creating an index or a pointer to the location of data in a database table. It helps in improving query performance and overall database efficiency. Indexing is especially useful in large databases with thousands of records.
When designing a database, it’s important to choose the right columns to index. Indexes should be created on columns that are frequently searched or used in a WHERE or JOIN clause. Creating too many indexes can slow down insert and update operations, so it’s important to strike a balance between the number of indexes and their effectiveness.
Another important consideration is the type of index to use. In Microsoft SQL Server, for example, there are several types of indexes, including clustered, nonclustered, and full-text indexes. Each type has its own advantages and disadvantages and should be chosen based on the specific needs of the database.
Creating and maintaining indexes requires careful planning and execution. It’s important to regularly monitor and optimize indexes to ensure their efficiency. This can involve rebuilding or reorganizing indexes to reduce fragmentation and updating statistics to help the query optimizer make better decisions.
Overall, indexing is a crucial aspect of designing an efficient database. By choosing the right columns to index and using the appropriate index types, you can improve query performance and enhance the overall efficiency of your database.
Example SQL Code:
CREATE INDEX idx_customer_name ON customers (customer_name);Efficient Data Types and Constraints
Designing a database involves making choices about the types of data that will be stored and how those data will be constrained. Choosing the right data types and constraints is essential to achieving an efficient database design.
Data Types: When selecting data types for database tables, the goal is to choose the smallest type that accommodates the data. This can help minimize storage requirements and reduce the amount of memory needed to process queries. For example, choosing an appropriate character set for string data can save space. In SQL Server, NVARCHAR data types use double the storage space of VARCHAR data types. If the column will not contain non-English text data, VARCHAR would be a more efficient choice.
Constraints: Constraints are rules that limit the values that can be entered into a column. Database designers should use constraints to help ensure data integrity. For example, the PRIMARY KEY constraint ensures that each row in a table is unique, which can help prevent data duplication and reduce storage requirements. The FOREIGN KEY constraint ensures that data in one table is linked to data in another table, which can help ensure the accuracy of data and reduce errors.
Sample SQL Code Example:
| Column Name | Data Type | Constraints |
|---|---|---|
| employee_id | INT | PRIMARY KEY |
| first_name | VARCHAR(50) | NOT NULL |
| last_name | VARCHAR(50) | NOT NULL |
| VARCHAR(100) | UNIQUE | |
| hire_date | DATETIME | – |
In the example above, the employee_id column has been designated as the primary key, ensuring that each row in the table is unique. The first_name and last_name columns are required and cannot be left blank, which helps ensure data completeness. The email column has a unique constraint applied, which ensures that each email address entered into the table is unique. Finally, the hire_date column does not have any constraints, as it is not required for every row.
Denormalization for Performance Optimization

Database normalization is the process of organizing data in a database to reduce data redundancy and improve data integrity. Normalization makes the database more efficient and easier to maintain, but it can also lead to slower performance in certain situations.
Denormalization is the process of intentionally adding redundancy to a database for the purpose of improving performance. This means breaking some of the normalization rules to create redundant data in the database.
There are several approaches to denormalizing a database, including:
- Duplicating data in multiple tables to reduce joins
- Addition of new tables with pre-joined data
- Adding calculated columns to tables to reduce the need for complex calculations in queries
Denormalization can significantly improve query performance in certain situations, but it should be used judiciously. It can lead to inconsistent data if not implemented carefully, and it can also make the database more difficult to maintain and update.
One common use of denormalization is in data warehousing. In this scenario, the goal is to perform complex analytics on large datasets, and denormalization can significantly improve query performance.
Here is an example of using denormalization to improve performance:
Let’s say you have a database with two tables: Orders and OrderDetails. The Orders table contains order information such as the order date and customer ID, while the OrderDetails table contains information about the products ordered, including the product ID, quantity, and price.
If you wanted to retrieve a list of all orders and the total sales for each customer, you would need to join the two tables and perform a calculation on the OrderDetails table to get the total sales for each order.
However, by denormalizing the database and adding a column to the Orders table for total sales, you can eliminate the need for the join and the calculation, greatly improving performance:
| Orders | |||
|---|---|---|---|
| OrderID | OrderDate | CustomerID | TotalSales |
| 1 | 2024-01-01 | 123 | 50.00 |
| 2 | 2024-01-02 | 456 | 75.00 |
In this example, the TotalSales column is calculated and updated each time an order is placed or modified. This means that when you need to retrieve a list of orders and their total sales, you can do so without joining to the OrderDetails table or performing any calculations, resulting in much faster performance.
However, it’s important to note that denormalization can make the database more difficult to maintain. If the OrderDetails table is updated, the TotalSales column in the Orders table will need to be updated as well to ensure consistency, which can be challenging in a large and complex database.
Denormalization can be a powerful tool for improving database performance, but it should be used with caution. It’s important to carefully consider the tradeoffs between performance and data integrity, and to only denormalize when necessary for specific use cases.
Data Partitioning and Sharding
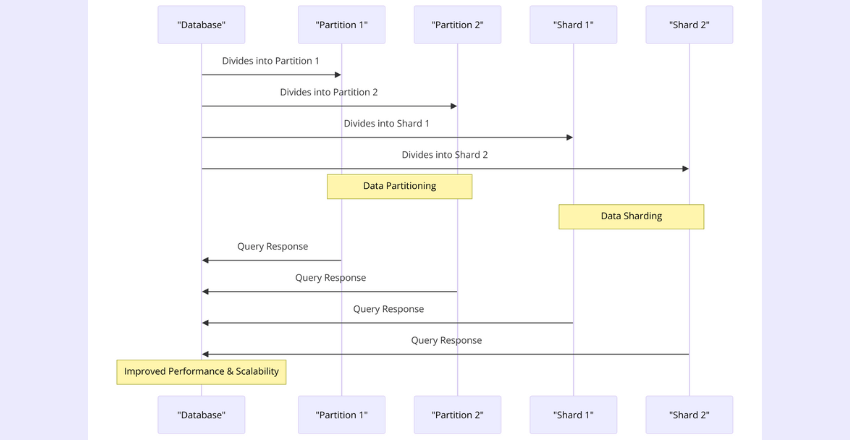
When dealing with large amounts of data, it can become increasingly difficult to manage every aspect of a database on a single server. This is where data partitioning and sharding come into play.
Data partitioning involves splitting a large table into smaller, more manageable parts, while sharding is a technique that involves dividing a database horizontally across multiple servers.
By dividing data across multiple servers, data partitioning and sharding can improve performance and scalability. This is because it allows for faster queries and more efficient data processing.
However, it is important to note that implementing data partitioning and sharding can be complex and requires careful planning. It is crucial to choose the right partitioning and sharding techniques for your database, as well as carefully configure and monitor the servers to ensure optimal performance.
Some common techniques for data partitioning include range partitioning, hash partitioning, and list partitioning. For sharding, there are several approaches, including horizontal sharding, vertical sharding, and hybrid sharding.
Overall, data partitioning and sharding can be valuable tools for improving the efficiency and scalability of your database. However, it is important to carefully consider the implementation and monitoring of these techniques to ensure optimal performance.
Optimizing Queries and Database Operations
Optimizing queries and database operations is an essential step in designing an efficient database. By optimizing queries, you can reduce the time it takes to retrieve data and improve overall database performance. Here are some tips and techniques to help you optimize your queries and operations:
- Use indexes: Indexes are essential for efficient query performance. They enable the database to quickly locate data in a table. Be sure to create indexes on the columns you frequently search, sort, or join.
- Avoid using wildcard characters: When searching for data, avoid using wildcard characters at the beginning of a search string. It forces the database to scan the entire table and slows down performance.
- Limit result sets: When retrieving data, limit the number of results returned. Use the TOP or LIMIT command to restrict the number of rows retrieved.
- Normalize your data: Normalization is critical for database efficiency. By breaking down tables into smaller, more manageable pieces, you can avoid redundancy and improve performance.
When optimizing database operations, consider the following:
- Batch processing: Divide database operations into batches to improve performance. By processing groups of queries at a time, you can reduce the amount of time spent on processing.
- Optimize data retrieval: Use efficient data retrieval techniques such as stored procedures, views, and query optimization to improve database performance.
- Performance tuning: Regularly tune your database by analyzing query performance and adjusting settings as needed.
Here is an example SQL query that demonstrates the use of an index:
SELECT * FROM products WHERE product_name LIKE 'apple%' AND category_id = 5;In this example, an index on category_id and product_name would improve performance by enabling the database to quickly locate the desired data. By optimizing queries and operations, you can improve database performance, reduce overhead, and ensure the efficient functioning of your database system.
External Resources
https://www.ibm.com/docs/en/i/7.3?topic=database-performance-query-optimization
FAQ
1. What are the key principles of database normalization, and how do they improve database design?
FAQ Answer: Database normalization is a systematic approach to minimize redundancy and dependency by organizing fields and table of a database. The key principles include:
- 1NF (First Normal Form): Ensures each table cell contains a single value and entry per column is unique.
- 2NF (Second Normal Form): Achieves 1NF and separates data into tables for entities requiring a primary key.
- 3NF (Third Normal Form): Achieves 2NF and removes transitive dependency.
Normalization improves design by reducing redundancy, improving data integrity, and facilitating easier updates.
Code Sample:
-- Before Normalization (Combined Table)
CREATE TABLE Sales (
SaleID INT,
CustomerName VARCHAR(100),
ProductName VARCHAR(100),
SaleDate DATE
);
-- After Normalization (Normalized Tables)
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
CustomerName VARCHAR(100)
);
CREATE TABLE Products (
ProductID INT PRIMARY KEY,
ProductName VARCHAR(100)
);
CREATE TABLE Sales (
SaleID INT PRIMARY KEY,
CustomerID INT,
ProductID INT,
SaleDate DATE,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID),
FOREIGN KEY (ProductID) REFERENCES Products(ProductID)
);Explanation: The initial table combines customer and product details with sales records, leading to redundancy. After applying normalization principles, data is organized into separate tables linked by foreign keys, reducing redundancy and enhancing data integrity.
2. How does effective indexing enhance database performance?
FAQ Answer: Indexing is a data structure technique used to speed up the retrieval of records in a database table. Effective indexing enhances database performance by allowing the database server to find and retrieve specific rows much faster than without an index.
Code Sample:
-- Creating an index on a frequently searched column
CREATE INDEX idx_customer_name ON Customers (CustomerName);Explanation: In this example, an index is created on the CustomerName column of the Customers table. This index helps the database quickly locate customer records based on names, significantly speeding up query performance for searches, joins, and where clauses involving the CustomerName.
3. Why is defining foreign keys important in database design, and how do they contribute to data integrity?
FAQ Answer: Foreign keys are crucial for enforcing referential integrity, ensuring that relationships between tables remain consistent. They link rows in one table to rows in another, ensuring that actions like updates and deletes do not lead to orphan records or inconsistent data.
Code Sample:
CREATE TABLE Orders (
OrderID INT PRIMARY KEY,
CustomerID INT,
OrderDate DATE,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);Explanation: The FOREIGN KEY in the Orders table ensures that every CustomerID in the Orders table matches a valid CustomerID in the Customers table. This prevents orders from being associated with non-existent customers, thereby maintaining data integrity across the database.
